




























































What Are the Tools of Machine Learning?
Learn about the most widely used tools in machine learning, including frameworks, libraries, and platforms that support model building and data analysis.

Machine learning is now used in almost every industry, from online shopping recommendations to fraud detection and business forecasting. Behind every successful machine learning project are the right tools that help collect data, build models, test results, and run solutions in real situations.
Many beginners think machine learning is only about algorithms, but the real work involves choosing the correct tools at each stage of the process. Understanding these tools makes learning easier and helps professionals solve real data problems with confidence while building solutions that work effectively in real-world environments.
Understanding the Basics of Machine Learning
Machine learning is about teaching computers to learn from data and make decisions or predictions. It includes different types of learning:
Supervised Learning
In supervised learning, we use data that already has the answers (labels). The model learns from this data to make predictions about new data. Examples include:
-
Predicting house prices
-
Classifying emails as spam or not
-
Recognizing images or speech
Unsupervised Learning
In unsupervised learning, we give the model data without labels. The goal is to find patterns or groupings in the data. Examples include:
-
Grouping customers based on shopping behavior
-
Reducing the number of features to make data easier to understand
Reinforcement Learning
This type is based on learning from actions and rewards. The model (called an agent) interacts with an environment and learns to make better decisions over time. Examples include:
-
Teaching a robot to walk
-
Training self-driving cars
Types of Machine Learning Algorithms
Different tasks need different types of algorithms. Here are the main ones:
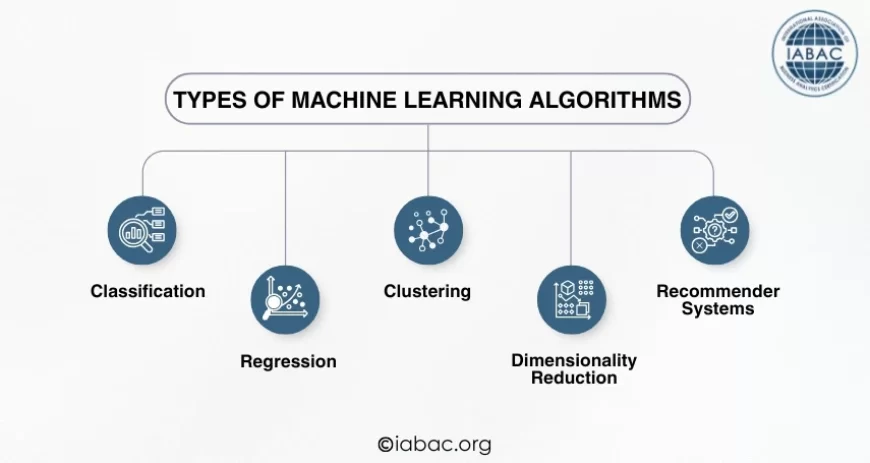
-
Classification: Used when the goal is to place data into categories (e.g., spam or not spam).
-
Regression: Predicts numbers, like sales or temperature.
-
Clustering: Groups similar items when no labels are provided.
-
Dimensionality Reduction: Makes data simpler while keeping important parts.
-
Recommender Systems: Suggests products, movies, or content based on user activity.
Tools Used in Data Preprocessing
Before using machine learning, data must be cleaned and prepared. These tools help in that process:
Data Collection and Storage
Tools like MySQL, PostgreSQL, and MongoDB help store data. Cloud platforms like Amazon S3 and Google Cloud Storage make it easy to store and access data from anywhere.
Data often comes with errors or missing parts. Libraries like Pandas in Python help clean data, remove duplicates, fill in missing values, and correct errors. Tools like Seaborn and Matplotlib help visualize the problems in the data.
Feature Engineering
This means creating useful inputs for models. Tools like Scikit-Learn help with feature selection, extraction, and scaling. Methods like PCA and t-SNE help reduce the number of features while keeping key information.
Popular Programming Languages for Machine Learning
Some programming languages are widely used for machine learning:
-
Python: Easy to learn and has many helpful libraries like NumPy, Pandas, and Scikit-Learn.
-
R: Good for statistics and data analysis. Common in research.
-
Julia: Known for its speed. Used when working with large datasets or doing heavy calculations.
Machine Learning Frameworks and Libraries
Frameworks help save time by giving ready-made tools and code. Some useful ones are:
-
Scikit-Learn: Great for regular machine learning tasks like classification or regression.
-
TensorFlow and PyTorch: Used to build and train deep learning models.
-
Keras: A simple way to build deep learning models using TensorFlow.
-
XGBoost and LightGBM: Known for making strong predictive models, especially in competitions.
Tools for Writing and Testing Code
Writing and testing code is easier with the right environment:
-
Jupyter Notebook: Helps you write code and notes in one place. Great for trying ideas.
-
Google Colab: Works like Jupyter, but in the cloud. You can share and run code with others.
-
VS Code and Spyder: Good code editors with features like auto-complete and debugging.
-
RStudio: Best for those using the R language.
Data Visualization Tools
Showing data clearly helps understand patterns and results. Some useful tools include:
-
Matplotlib: A basic Python library for charts and graphs.
-
Seaborn: Built on top of Matplotlib, easier to use for beautiful visualizations.
-
Plotly: Creates interactive charts for the web.
-
Power BI: Helps build dashboards to track and understand data.
Model Testing and Evaluation
Testing models is important to make sure they give correct results. Some ways to do this are:
-
Cross-Validation: Splits data into parts to test how the model performs on different data.
-
Metrics:
-
Accuracy: How often the model is right.
-
Precision & Recall: Help when classes are unbalanced.
-
F1-Score: Combines precision and recall.
-
Confusion Matrix: Shows correct and incorrect results in a table.
-
ROC Curve & AUC: Show how well the model separates classes.
-
Hyperparameter Tuning: Finds the best settings for your model using tools like grid search.
Deployment and Production Tools
After building a model, you need to put it to use. These tools help:
-
Jenkins: Automates code testing and deployment.
-
Docker: Packages code and tools so it runs the same everywhere.
-
Kubernetes: Manages large systems and makes sure everything runs smoothly.
-
Ansible: Helps manage configurations.
-
Prometheus: Watches how systems perform in real-time.
Keeping Models Working Well Over Time
Once a model is deployed, you need to monitor and maintain it. Here’s how:
-
Prometheus, Grafana, and ELK Stack help track how models perform—like accuracy and speed.
-
TensorFlow Extended (TFX) and Apache Airflow help with retraining models using new data.
-
OpenNMS and Zabbix detect problems like drifting performance or changes in data quality.
The Complete Machine Learning Workflow and Tool Stack
To understand machine learning clearly, it helps to see the entire journey of a project. Most real-world projects follow a workflow:
-
Data Collection: Gathering data from databases, APIs, or business systems.
-
Data Preparation: Cleaning and transforming raw data.
-
Model Building: Training algorithms using frameworks and libraries.
-
Experiment Tracking: Testing multiple models and comparing results.
-
Deployment: Making the model available for real users.
-
Monitoring: Checking performance after deployment.
Thinking in terms of workflow helps beginners understand how different tools connect.
Cloud-Based Machine Learning Platforms
Today, many companies build machine learning solutions directly in the cloud instead of managing local systems.
Cloud platforms provide ready environments for training, testing, and deploying models. These platforms reduce setup time and allow teams to focus more on solving business problems.
Benefits include:
-
Faster development
-
Easy collaboration
-
Scalable computing power
-
Secure data storage
Cloud machine learning platforms are widely used in industries like finance, retail, healthcare, and marketing analytics.
AutoML and Low-Code Machine Learning Tools
Not everyone who works with machine learning is a programmer. Many modern tools allow users to build models with minimal coding.
AutoML tools help by:
-
Selecting algorithms automatically
-
Finding the best parameters
-
Comparing model performance
-
Reducing development time
These tools are helpful for beginners, analysts, and business professionals who want insights without deep technical work.
MLOps: Managing Machine Learning in Production
Building a model is only the beginning. Real value comes when models run reliably in production systems.
MLOps focuses on:
-
Version control for models
-
Automated training pipelines
-
Continuous testing
-
Model monitoring
-
Collaboration between data teams and engineering teams
Tools like MLflow, Kubeflow, and DVC help organize experiments and keep track of model changes over time.
Generative AI and Modern Machine Learning Tools
Machine learning has expanded into new areas such as language understanding, image generation, and conversational systems.
Modern projects often use:
-
Pretrained language models
-
Natural language processing libraries
-
Model hubs where developers reuse trained models
These tools allow businesses to build chat systems, recommendation engines, document analysis solutions, and automated customer support systems faster than before.
Machine Learning Tools for Different Industry Use Cases
Different industries use different tool combinations:
Marketing Analytics
Customer segmentation, recommendation systems, and campaign prediction models.
Finance
Fraud detection, risk scoring, credit prediction, and forecasting.
Healthcare
Disease prediction, medical image analysis, and patient monitoring systems.
Retail and E-commerce
Demand forecasting, pricing optimization, and personalized product suggestions.
Understanding the use case helps professionals choose the right tools instead of learning everything at once.
Machine Learning Tool Roadmap for Beginners
If you are starting your journey, learning tools step by step makes the process easier.
Beginner Level
-
Pandas
-
Scikit-Learn
-
Jupyter Notebook
Intermediate Level
-
TensorFlow or PyTorch
-
Data visualization tools
-
Model evaluation techniques
Advanced Level
-
Docker
-
Kubernetes
-
MLOps tools
-
Cloud deployment platforms
Following a roadmap helps avoid confusion and builds confidence gradually.
Emerging Trends in Machine Learning 2026
Machine learning continues to evolve quickly. Some important trends include:
-
Automated machine learning adoption
-
Responsible and ethical AI practices
-
Cloud-first machine learning development
-
Real-time prediction systems
-
Integration of analytics with business decision platforms
Professionals who understand both tools and business problems will have strong career opportunities.
The Role of Ethics in Machine Learning
As machine learning becomes a bigger part of our lives, we must think about fairness, transparency, and avoiding bias. Tools for bias checking and explainable AI help build systems that treat all people fairly and build trust. This is where learning from trusted sources matters.
Why Choose Machine Learning Certification from IABAC
Earning an Artificial Intelligence and Machine Learning certification is a valuable way to validate your skills and strengthen your professional profile. IABAC offers globally recognized certifications trusted by industry professionals across different domains. These certifications focus on practical knowledge, industry relevance, and real-world applications rather than theory alone. A recognized certification helps professionals showcase their expertise, build credibility, and confidently apply machine learning concepts and tools in real business environments.



-
 Nithra BGreat information , now I know which tools to use for machine learning!
Nithra BGreat information , now I know which tools to use for machine learning! -
Kalyan DBeen searching for this for a while, now i got to know what i exactly wanted to know. thanks!









