





























































What Are the Top Data Science Interview Questions
Get ready for your data science interview with key questions and insights on data science marketing. Our guide helps you prepare with essential information.

When I first started preparing for data science interviews, I quickly realized how important it was to focus on the right Data Science Interview Questions. These questions can make or break your chances. Over the years, I’ve been through many interviews and faced various challenges. Through these experiences, I've learned what really matters and how to approach these situations confidently. Share the most common Data Science Interview Questions I faced and how I handled them, so you can be better prepared for your interviews in the competitive field of data science.
The Growing Need for Data Science Professional
Businesses from all sectors are turning to data to make smarter decisions, improve their operations, and foster innovation. This increasing need comes from the rapid growth of data and the necessity for skilled people to analyze and use it effectively. The key to this demand is a strong foundation in data science. Companies are looking for professionals who can handle complex data tasks and have credentials like Certified Data Science Developer, Certified Machine Learning Expert, and Certified Data Scientist. These certifications show a high level of skill and knowledge.
What is the biggest challenge in data science?
Data science can offer great benefits to businesses, but it comes with several challenges that can slow things down. Here are some common issues faced by data scientists and simple ways to overcome them.

1. Data Preparation
Challenge: Raw data is often messy, incomplete, or inconsistent.
Solution: Use automated tools for cleaning and organizing data, and set up strong data management practices to ensure high-quality data.
2. Integrating Data from Different Sources
Challenge: Data comes from many places (CRM, IoT, social media), which makes combining it difficult.
Solution: Use ETL (Extract, Transform, Load) tools or data lakes to bring all data together and make it easier to manage.
3. Explaining Results to Non-Technical People
Challenge: Data scientists often find it difficult to explain technical results to those without a technical background.
Solution: Avoid technical jargon, use simple charts and graphs, and focus on how the results can help the business.
4. Data Security and Privacy
Challenge: Protecting sensitive data while following privacy laws and security protocols can be tricky.
Solution: Use encryption, anonymize data when possible, and run regular audits to make sure data security and privacy laws like GDPR are followed.
5. Choosing the Right KPIs
Challenge: Using vague or unclear KPIs can lead to misleading conclusions.
Solution: Set SMART KPIs (Specific, Measurable, Achievable, Relevant, Time-bound) that align directly with business goals, and review them regularly.
Top Data Science Interview Questions and Answers
Here are some common Data Science Interview Questions that candidates often face. These questions cover various topics like statistics, machine learning, data cleaning, and problem-solving. Preparing for these will help you show your skills and knowledge as a data scientist. Preparing for a data science interview? Here are ten common Data Science Interview Questions along with simple answers to help you get ready. For more helpful resources, check out the IABAC site.
1. What’s the difference between supervised and unsupervised learning?
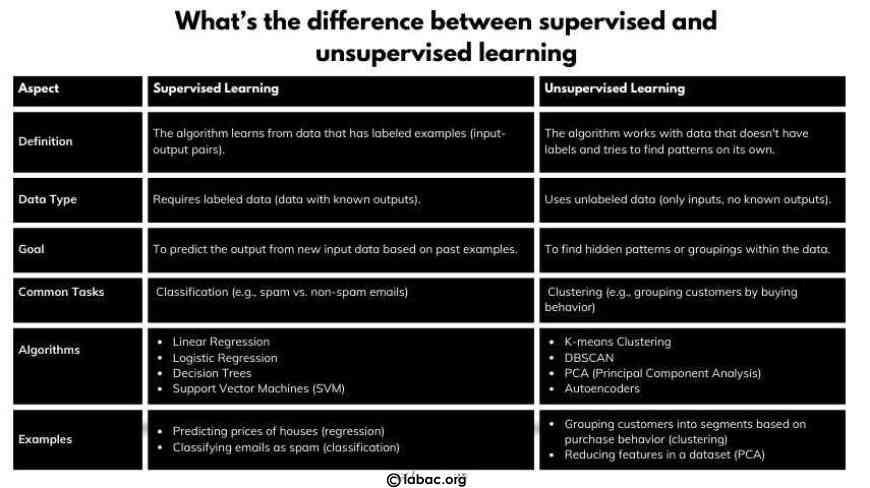
- Supervised Learning: The model is trained using data that has both inputs and known outputs. Example: Linear Regression, Decision Trees.
- Unsupervised Learning: The model works with data that doesn’t have output labels. It tries to find patterns or groupings in the data. Example: K-means, PCA.
2. What is overfitting, and how can you avoid it?
- Overfitting happens when the model learns too much from the training data, including noise, which makes it perform poorly on new data.
- To prevent overfitting:
- Use simpler models.
- Apply cross-validation.
- Use regularization (L1 or L2).
- Gather more data.
- Use dropout in neural networks.
3. What is cross-validation, and why is it important?
Cross-validation is a method used to test how well a model works on new, unseen data. It involves splitting the data into several parts. The model is trained on some parts (training data) and tested on the remaining parts (test data). This process is repeated multiple times, making sure every data point is used for both training and testing.
Why Cross-Validation is Important:
- Reduces Overfitting: It helps prevent the model from being too focused on a specific set of data, making it more likely to work well on new data.
- Better Evaluation: It gives a more reliable idea of how well the model will perform on data it hasn’t seen before by averaging results from different tests.
- Improves Generalization: It makes sure the model can handle real-world data, not just the data it was trained on.
4. What are the assumptions of linear regression?
- Linearity: The relationship between input and output is linear.
- Independence: Errors should not be correlated.
- Homoscedasticity: Constant variance of errors.
- Normality: Residuals should be normally distributed.
Violating these assumptions can make the model less reliable.
5. How would you deal with missing or corrupted data?
- Remove data: Delete rows with missing values if they are few.
- Impute data: Fill missing values with mean, and median, or use algorithms to predict missing data.
- Use algorithms that handle missing data: Some models like Decision Trees can work with missing data directly.
6. What is feature engineering, and why is it important?
Feature engineering is the process of changing raw data into useful features that help machine learning models work better. This involves making new features, picking important ones, and preparing the data (like scaling or encoding).
Why It's Important:
- Improves Accuracy: Good features help the model make better predictions.
- Prevents Overfitting: Removing unnecessary features helps the model work well on new, unseen data.
- Makes Models Easier to Understand: Good features can make the model's decisions clearer.
- Improves Efficiency: Some models work faster and more effectively with better features.
Examples:
- Creating Features: You might combine "date" and "time" into a new feature like "day of the week."
- Scaling: Standardizing data so algorithms like KNN or neural networks perform better.
- Encoding: Turning categorical data into numbers for the model to understand.
7. What is regularization, and why is it needed?
Regularization is a method used in machine learning to stop models from becoming too complex and overfitting the training data. It adds a penalty to the model's loss function, encouraging the model to be simpler and better at making predictions on new data.
Why It's Important:
- Prevents Overfitting: Regularization helps avoid the model learning noise from the data, allowing it to generalize better.
- Simplifies the Model: It makes the model use fewer important features, reducing the risk of capturing irrelevant patterns.
- Improves Predictions: A regularized model is more likely to perform well on new, unseen data.
Types of Regularization:
- L1 Regularization (Lasso): This method adds a penalty based on the absolute values of the model's coefficients, which can lead to some coefficients being set to zero. This helps select the most important features.
- L2 Regularization (Ridge): This adds a penalty based on the square of the coefficients, shrinking them towards zero without making them exactly zero.
In a Data Science Interview Questions setting, understanding regularization is key to explaining how to improve a model's performance and prevent overfitting.
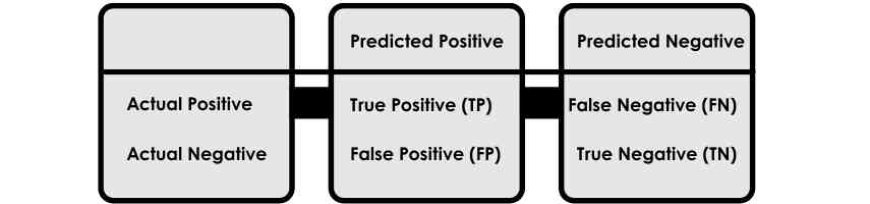
8. What is a confusion matrix?
A confusion matrix is a tool used to assess how well a classification model performs. It compares the model's predicted classifications to the actual results, showing where the model gets things right and where it makes errors.
Structure of a Confusion Matrix:
1. Accuracy: This tells you how often the model is correct, considering both true positives and true negatives.
- Formula:

2. Precision: This measures how many of the predicted positives are actually correct.
- Formula:
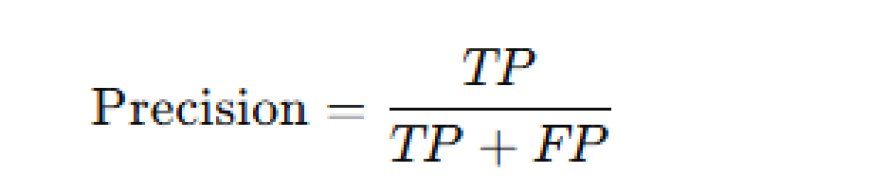
3. Recall (Sensitivity): This shows how many of the actual positives the model correctly identified.
- Formula:
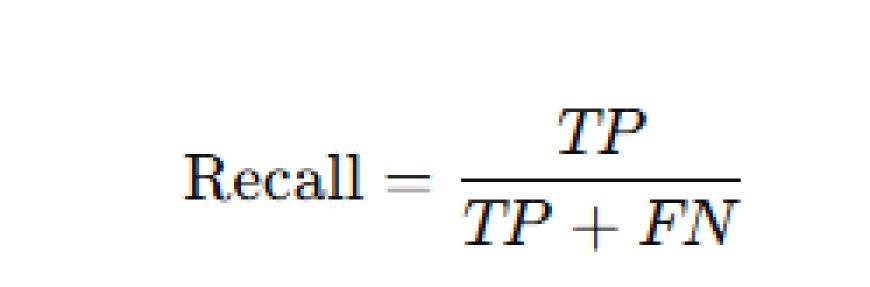
4. F1-Score: This combines precision and recall into one number to give a balanced view of the model's performance.
- Formula:
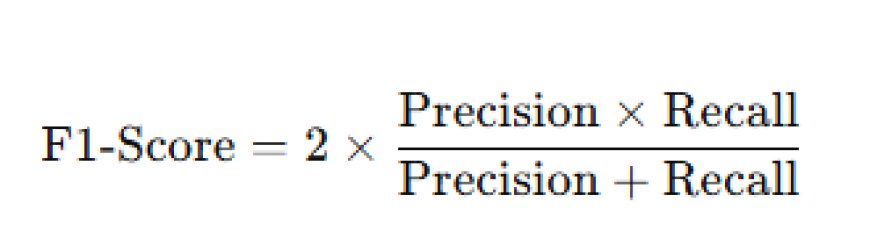
9. What’s the difference between parametric and non-parametric models?
When you're preparing for Data Science Interview Questions, you'll likely come across the terms parametric and non-parametric models. These refer to different types of statistical models, and the key difference lies in how they handle data and make predictions.
Parametric Models:
- Assume a specific data pattern: These models believe the data follows a certain pattern or distribution (like straight lines or bell curves).
- Simple to use: They work with fewer data points because they have a fixed set of parameters to estimate.
- Examples:
- Linear Regression: Assumes the relationship between variables is a straight line.
- Logistic Regression: Assumes the data fits a specific curve for classification.
- Naive Bayes: Assumes a certain distribution (like Gaussian) for each feature.
- Pros: Faster to train, easier to understand, and simpler to compute.
- Cons: They can perform poorly if the assumed pattern doesn’t match the actual data.
Non-Parametric Models:
- No assumptions about the data: These models don’t assume any specific pattern or distribution. They’re more flexible.
- Need more data: Since they don't rely on fixed parameters, they may need more data to make accurate predictions.
- Examples:
- Decision Trees: Splits data into branches based on feature values, with no assumptions.
- K-Nearest Neighbors (K-NN): Looks at nearby data points to make predictions, with no assumptions.
- Kernel Density Estimation: Estimates the probability of data based on how close the points are to each other.
- Pros: More flexible and can handle complicated data patterns.
- Cons: Can be slow, require a lot of data, and might overfit if there’s not enough data.
10. How do you handle imbalanced classes in classification problems?
- Resampling:
- Oversample the minority class or undersample the majority class.
- Use different evaluation metrics: Accuracy might not be helpful. Use precision, recall, or F1-score instead.
- Use algorithms that can handle imbalanced data: Some algorithms like Random Forest and Gradient Boosting allow you to set class weights.
By following these strategies, you’ll be well-equipped to handle Data Science Interview Questions and showcase your expertise. For more resources and practice materials, visit IABAC to boost your preparation.












