



























































Introduction to Deep Learning
Learn the fundamentals of deep learning, its key concepts, and practical applications in various fields like AI, neural networks, and machine learning.

When I first got into Deep Learning, I was amazed by how quickly the field was growing. As someone passionate about Artificial Intelligence, stepping into Deep Learning opened up so many new possibilities for me. To strengthen my understanding, I decided to pursue an Artificial Intelligence Certification. This certification helped me see how these technologies are applied in the real world. Deep Learning has changed many industries, from healthcare to finance, and it keeps shaping the future. By sharing my experience, I hope you can see how powerful and important this technology is.
What is Deep Learning?
Deep learning uses a type of model called artificial neural networks (ANNs), which are designed to mimic how the human brain works. These networks are made up of layers, and they learn by processing data step by step. The term "deep" refers to the many layers that help the model learn increasingly complex patterns in the data.
Why Deep Learning is Important
Deep learning has become one of the most influential technologies in modern artificial intelligence. One major reason for its importance is its ability to handle huge amounts of data. Today, organizations collect data from websites, mobile apps, sensors, and many other sources. Deep learning models can analyze this large volume of information and identify patterns that might be difficult for traditional algorithms to detect.
Another reason deep learning is important is its ability to improve accuracy in many prediction tasks. From detecting diseases in medical images to recommending products in online stores, deep learning systems are helping businesses make better decisions. As computing power and data availability continue to grow, the role of deep learning will only become more significant.
Deep Learning vs Machine Learning
Many people often confuse deep learning with machine learning, but they are not exactly the same. Deep learning is actually a subset of machine learning.
Machine learning typically uses algorithms that require humans to define features in the data. For example, when building an image classification model, engineers might need to identify useful characteristics such as shapes or edges manually.
Deep learning, on the other hand, automatically learns these features using multiple layers of neural networks. This makes deep learning especially useful for complex tasks such as image recognition, speech processing, and natural language understanding.
In simple terms, machine learning works well with smaller datasets and simpler models, while deep learning performs better when large datasets and powerful computing resources are available.
How Deep Learning Works
Deep Learning (DL) is a powerful part of machine learning (ML) and artificial intelligence (AI). It has made a big impact in areas like healthcare, robotics, and self-driving cars. The reason it’s so successful is its ability to handle and learn from large amounts of data using neural networks. In this guide, we will explain how deep learning works in simple terms, covering the key ideas, basic math, and matrices that are used to train deep learning models.
Artificial Neural Networks (ANNs)
An artificial neural network consists of "neurons" (or nodes) arranged in layers. These neurons are connected by "weights" and "biases," and they work together to process input data and produce an output.
There are three types of layers in a typical neural network:

- Input Layer: This layer receives the raw data.
- Hidden Layers: These layers do most of the learning and adjust parameters as the model is trained.
- Output Layer: This layer gives the final result, like a prediction or classification.
Structure of a Neural Network
Here’s how the basic structure of a neural network works:
1 Neurons and Activation Functions
Each neuron receives input from the previous layer, applies a weighted sum, adds a bias, and then passes it through an activation function. The activation function determines how the signal is passed forward.
The output of a neuron can be calculated as:
y=σ(Wx+b)
Where:
- xxx is the input,
- WWW is the weight matrix,
- bbb is the bias term,
- σ\sigmaσ is the activation function,
- yyy is the output.
Activation functions like ReLU, Sigmoid, and Tanh help the network learn complex patterns by introducing non-linearity.
2 How Information Moves Through the Network
Each neuron computes a sum of its inputs, applies a bias, and uses the activation function to produce an output. This process repeats across multiple layers until the network produces its final output.
Training a Neural Network
Training a neural network means adjusting the weights and biases to make sure the network can give accurate predictions. The process includes backpropagation and gradient descent.
1 Forward Propagation
In forward propagation, input data passes through the network, and an output is generated. This output is compared to the actual target (the correct answer).
2 Loss Function
The loss function measures how far the network's output is from the correct target. The goal is to reduce this loss during training. Common loss functions include:
- Mean Squared Error (MSE) for regression tasks.
- Cross-Entropy Loss for classification tasks.
For predicted values y^\hat{y}y^ and actual values yyy, the loss function is:
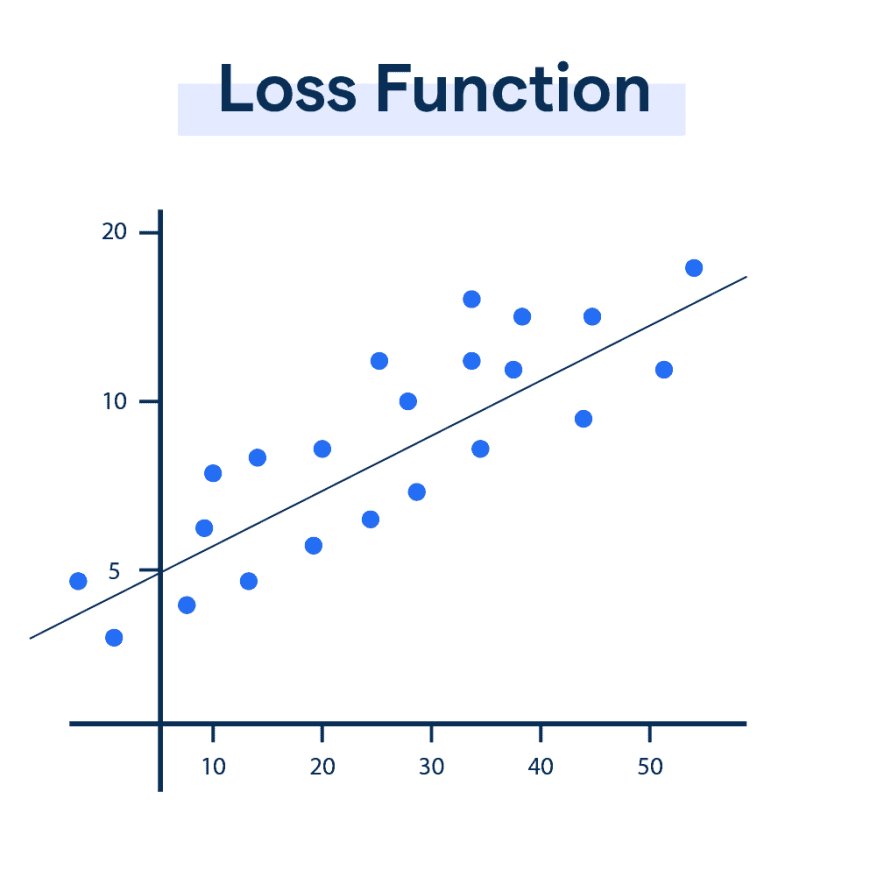
Where NNN is the number of data points.
3 Backpropagation
Backpropagation is a way to update the weights and biases by calculating how much each weight needs to change. This is done by computing the gradient of the loss function with respect to each weight.
The weight update rule is:
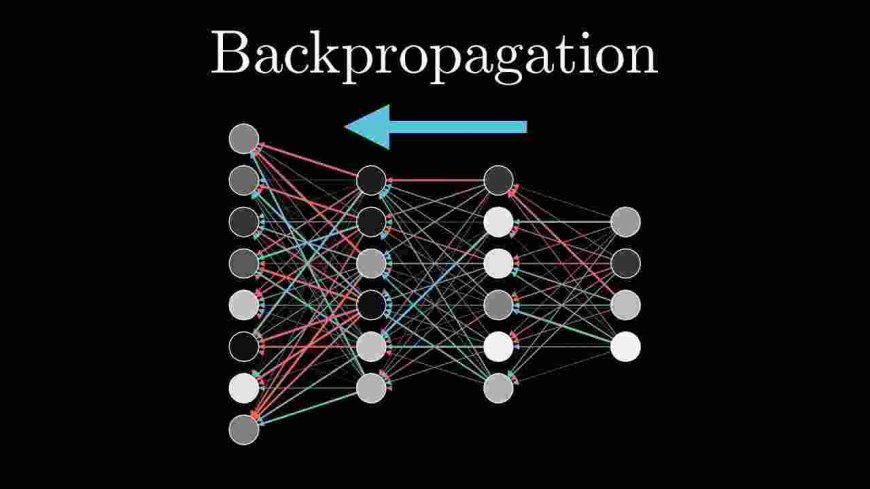
Where:
- η\etaη is the learning rate, which controls how big the steps should be during updates.
4 Gradient Descent
Gradient descent is an algorithm used to minimize the loss function. It makes adjustments to the weights to reduce the loss. There are different types of gradient descent:
- Batch Gradient Descent uses the entire dataset for each update.
- Stochastic Gradient Descent (SGD) uses one data point at a time.
- Mini-batch Gradient Descent uses a small batch of data for each update.
Types of Deep Learning Models
There are different types of deep learning models for specific tasks. Here are some of the most common ones:

- Feedforward Neural Networks (FNN): This is the simplest kind of network, where data moves from the input layer to the output layer without any feedback loops.
- Convolutional Neural Networks (CNNs): CNNs are used for image tasks. They use convolutional layers to automatically detect features like edges, shapes, and textures in images.
- Recurrent Neural Networks (RNNs): RNNs are designed for sequential data like time series or text. They have loops that let them remember previous inputs, making them useful for tasks like language processing and speech recognition.
- Generative Adversarial Networks (GANs): GANs consist of two networks: a generator that creates fake data and a discriminator that tries to tell real from fake data. They are often used for creating realistic images and videos.
Real-World Applications of Deep Learning
Deep learning is widely used across many industries today. Its ability to analyze complex data has made it valuable in solving real-world problems.
In healthcare, deep learning models help detect diseases from medical images such as X-rays and MRI scans. Doctors can use these systems as decision-support tools to improve diagnosis accuracy.
In finance, deep learning is used to detect fraudulent transactions and identify unusual patterns in financial data. This helps banks reduce risks and protect customers.
In transportation, deep learning plays a key role in self-driving cars. These systems analyze images, detect obstacles, and make driving decisions in real time.
Deep learning is also widely used in voice assistants, recommendation systems, language translation, and facial recognition technologies.
Popular Deep Learning Frameworks
Building deep learning models from scratch can be complex. Fortunately, several frameworks make it easier for developers and researchers to design and train neural networks.
TensorFlow is one of the most widely used deep learning frameworks. It allows developers to build large-scale machine learning models and deploy them in production environments.
PyTorch is another popular framework known for its flexibility and ease of use. Many researchers prefer it for experimenting with new models.
Keras is a user-friendly framework that runs on top of TensorFlow. It simplifies model development and is widely used by beginners who are learning deep learning concepts.
These frameworks provide tools for building models, processing data, and training neural networks efficiently.
Advantages of Deep Learning
Deep learning offers several advantages that make it powerful for modern applications.
One major advantage is its ability to learn features from raw data automatically. Unlike traditional machine learning methods, deep learning does not require extensive manual feature engineering.
Another advantage is its high performance in complex tasks such as image recognition and natural language processing. Deep learning models often achieve higher accuracy when trained with large datasets.
Deep learning systems can also improve over time as they are exposed to more data, making them useful for long-term learning applications.
Limitations of Deep Learning
Despite its strengths, deep learning also has some limitations.
One challenge is the need for large datasets. Training deep learning models often requires thousands or even millions of examples.
Another limitation is the high computational cost. Deep learning models typically require powerful hardware such as GPUs to train efficiently.
Interpretability is also a challenge. Many deep learning models behave like "black boxes," making it difficult to understand how they make specific decisions.
Mathematics Behind Deep Learning
Deep learning relies on key mathematical concepts, such as linear algebra, calculus, and probability. Here’s a quick overview of important ideas:
1. Matrices and Vectors
Data is often represented as matrices. For example, an image can be represented as a matrix of pixel values. Operations such as matrix multiplication help calculate weighted sums in each layer of a neural network.
2. Gradient and Chain Rule
Backpropagation uses the gradient of the loss function to update the weights. The gradient tells us how much the loss will increase or decrease if we change the weights. The chain rule helps us compute gradients in each layer of the network.
3. Partial Derivatives
During backpropagation, we compute partial derivatives of the loss function with respect to each weight to determine how to adjust them in the right direction.
How to Start Learning Deep Learning
For beginners who want to enter the field, it helps to follow a structured learning path.
Start by learning programming languages such as Python, which is widely used in data science and artificial intelligence.
Next, build a strong foundation in machine learning concepts, statistics, and mathematics. Understanding linear algebra and calculus can make deep learning easier to grasp.
After that, practice using popular frameworks like TensorFlow or PyTorch. Working on small projects such as image classification or sentiment analysis can help you gain hands-on experience.
Consistent practice and experimentation are the best ways to develop deep learning skills.
The Future of Deep Learning
The future of deep learning looks extremely promising. As technology continues to evolve, deep learning systems are expected to become more efficient, accurate, and widely accessible.
Researchers are exploring new architectures and models that can learn with less data and require fewer computing resources. These advancements may allow deep learning to be applied in more industries and everyday applications.
Deep learning will likely play an even bigger role in fields such as healthcare, robotics, autonomous systems, and personalized digital experiences.
Deep learning is a powerful tool that can learn from large amounts of data and solve complex problems. By understanding how neural networks work, the importance of activation functions, and how the training process uses backpropagation and gradient descent, you can start to see how deep learning models are built and improved.
Although the mathematics behind deep learning may seem complex at first, breaking it down step by step makes it easier to understand. With continued learning and practice, anyone interested in artificial intelligence can begin exploring deep learning and building models that solve real-world problems.
If you plan to build strong expertise in this field, pursuing a structured program such as the Deep Learning Certification can help strengthen both theoretical knowledge and practical skills in AI and deep learning.












