



























































Data Science vs Data Engineering: Which Career Path Is Growing Faster in 2026?
Compare job growth, skills, salaries, and career opportunities to understand which path aligns with your goals and industry demand in 2026.

Data Science focuses on extracting insights and building machine learning models from data. Data Engineering focuses on building the pipelines and infrastructure that make those models possible. In 2026, the U.S. Bureau of Labor Statistics projects 34% growth for Data Scientists through 2034 (BLS, 2025), while industry reports show Data Engineering roles have grown as a share of total data team composition — now representing 55% of data professionals surveyed (Indeed Hiring Lab, 2026). Both careers pay well above six figures, both are future-proof, and both are genuinely worth your time. The question is which one fits you.
The Question That Keeps People Up at Data Science vs Data Engineering
You are at your desk. Browser tabs open. Seventeen YouTube videos paused. A notepad with two words circled and underlined and circled again: Data Science and Data Engineering. You have read ten articles. Each one contradicts the last. Your inbox has three course recommendations from newsletters you do not remember subscribing to.
Sound familiar? Good. That means you are taking this seriously.
The confusion is completely understandable. Both roles have "data" in the title. Both use Python. Both appear in the same job listings. Both promise good pay, interesting work, and a career that will not become obsolete in three years. But they are genuinely different paths — different tools, different mindsets, different day-to-day realities — and understanding that difference is the single most important thing you can do before committing months of learning time to one of them.
This blog lays it all out. Every statistic is sourced. Every comparison is grounded in real job market data. And by the end of it, you will know exactly which direction to take your data science roadmap in 2026.
What Does a Data Scientist Actually Do?
An introduction to data science often begins with a single idea: turning raw data into decisions. Data Scientists are the people who do that work. They analyze historical and real-time data, build predictive and prescriptive models, and communicate findings in a way that changes how a business behaves.
Their daily work includes exploratory data analysis, statistical modelling, machine learning model development, and — the part no one tells you about until you are already in the job — a staggering amount of data cleaning. Research consistently shows that data scientists spend 60–80% of their time preparing and cleaning data before any modelling begins (Forbes, 2024; Harvard Business Review). The insight work, the part you see in conference talks and LinkedIn posts, is a smaller slice of the job than most people expect.
A practical data science project looks like this:
A logistics company wants to predict which shipments will be delayed. A data scientist:
- Collects historical delivery records, weather data, and carrier performance data
- Cleans and merges the datasets, handles missing values, and engineers features (e.g., day-of-week, distance buckets, carrier tier)
- Trains a gradient boosting classifier (XGBoost or LightGBM)
- Evaluates with precision, recall, F1-score, and AUC-ROC
- Interprets the model using SHAP values to understand which features drive delays
- Presents a dashboard to operations leadership showing the top delay risk factors
- Recommends routing changes that reduce delays by an estimated 14%
The output is insight that drives action. That is the job.
Core tools of a Data Scientist: Python (NumPy, Pandas, scikit-learn, PyTorch, TensorFlow), R, SQL, Jupyter Notebooks, Tableau, Power BI, statistics, probability theory, and increasingly, MLOps platforms for model deployment and monitoring.
What Does a Data Engineer Actually Do?
If the data scientist is the chef, the data engineer built the kitchen, installed the appliances, sourced the ingredients, and made sure the gas lines do not leak. Without the data engineer, the data scientist has nothing clean, reliable, or structured to work with.
Data Engineers design, build, and maintain the infrastructure that moves data from where it is created to where it can be used — reliably, at scale, and on schedule. They build ETL (Extract, Transform, Load) pipelines, manage data warehouses and data lakes, orchestrate workflows, and ensure that the data flowing through an organisation is accurate, timely, and trustworthy.
A practical data engineering task looks like this:
A fintech company needs real-time transaction data available for fraud detection models. A data engineer:
- Sets up a Kafka stream to ingest transaction events in real-time
- Builds an Apache Flink job to process and enrich the stream (adding user risk scores, geolocation flags)
- Writes transformed data to a Delta Lake table on the cloud data warehouse
- Schedules and monitors the pipeline using Apache Airflow
- Sets up data quality checks and alerting so that if data volume drops anomalously, the on-call engineer is paged
- Ensures PII data is masked in compliance with GDPR and local financial regulations
The output is reliable data infrastructure. The fraud model cannot run without it.
Core tools of a Data Engineer: Python, SQL, Apache Spark, Apache Kafka, Apache Airflow, dbt (data build tool), Snowflake, BigQuery, Databricks, Delta Lake, AWS/GCP/Azure, Docker, and increasingly Terraform for infrastructure-as-code.
The 2026 Job Market: What the Numbers Actually Say
This is where many articles get vague. Let us be specific, because the data is available and it tells a clear story.
Data Science Job Growth
According to the U.S. Bureau of Labor Statistics Occupational Outlook Handbook (2025 update), Data Scientist employment is projected to grow 34% from 2024 to 2034 — classified as the 4th fastest-growing occupation in the entire U.S. economy, against a 3% average across all occupations (BLS, 2025). Total employment is projected to expand from 245,900 in 2024 to approximately 328,300 by 2034, with roughly 23,400 new job openings per year (BLS, 2025). The World Economic Forum's Future of Jobs Report 2025 ranked Big Data Specialists as the 1 fastest-growing job category globally, with AI and Machine Learning Specialists at #3. The WEF projects 170 million new jobs by 2030 in data and AI-related fields (WEF, 2025).
The global data science platform market is projected to grow from $13.6 billion in 2025 to $57.1 billion by 2032, driven by widespread adoption of data-driven decision-making across industries (Coherent Market Insights, 2025).
Data Engineering Job Growth
Data Engineering's growth story is slightly different in nature but equally compelling in scale. According to the StartUs 2026 Industry Report, the data engineering sector now employs over 150,000 professionals globally, with more than 20,000 new jobs created in the past year alone (StartUs, 2026).
Critically, industry composition data shows that data engineering is gaining share within data teams rapidly. A 2026 survey from Indeed Hiring Lab found that 55% of data professionals now identify primarily as data engineers, up from approximately 40% in 2021. Companies are investing significantly more in data infrastructure than in pure analytics: an estimated 60–70% of total data budgets now go to engineering, integration, and pipeline maintenance (Careery Blog, citing industry surveys, 2026). A 365 Data Science analysis of 1,000 job postings (2026) found Python appearing in 70% of data engineer job postings and SQL in 69%, with cloud skills and Spark experience being the most commonly required tools beyond the core languages.
Job Growth Trajectory: Data Science vs Data Engineering
(Illustrative index based on BLS, Indeed Hiring Lab, StartUs 2026 data)
|
Year |
Data Science (Growth Index) |
Data Engineering (Growth Index) |
|
2020 |
100 |
100 (~40% of data professionals) |
|
2021 |
118 |
112 |
|
2022 |
139 |
128 |
|
2023 |
163 |
145 |
|
2024 |
190 |
165 |
|
2025 |
218 |
189 |
|
2026 |
245 |
220 (~55% of data professionals) |
Note: 2026 values are projected/estimated.
Sources: U.S. Bureau of Labour Statistics (2025), Indeed Hiring Lab (2026), StartUs Insights (2026).
Both lines go up. Data Engineering's slope has steepened more sharply in recent years, driven by the AI infrastructure boom. The key insight: companies that hired data scientists in 2021–2023 are now urgently building the data infrastructure needed to support them.
Salary Comparison: Where the Money Actually Flows in 2026
Let us look at compensation data from multiple sources, because a single average number hides significant variation by experience level, location, and specialisation.
Data Scientist Salaries
The BLS (2025) reports a median annual salary of $112,590 for Data Scientists as of May 2024, with a full range of $58,510 to $174,790. Glassdoor (2026) places entry-level data scientist income at approximately $87,963, with senior professionals earning up to $150,769 annually. In top-paying states, California data scientists earn a median of $136,800 and Massachusetts $132,250 (BLS, 2025).
Data Engineer Salaries
Glassdoor data from early 2025 puts the average data engineer salary at $130,000 annually in the US (365 Data Science, 2026). Experience and specialisation create wide variance: senior data engineers at major technology companies report total compensation well above $180,000–$210,000, while mid-market roles in non-tech industries average closer to $105,000–$125,000 (Careery Blog, 2026).
Global Salary Picture
SALARY COMPARISON BY REGION AND LEVEL (2025–2026)
Sources: BLS (2025), Glassdoor (2026), IT Jobs Watch UK (2025-2026)
Data Science vs Data Engineering Salary Comparison (2026)
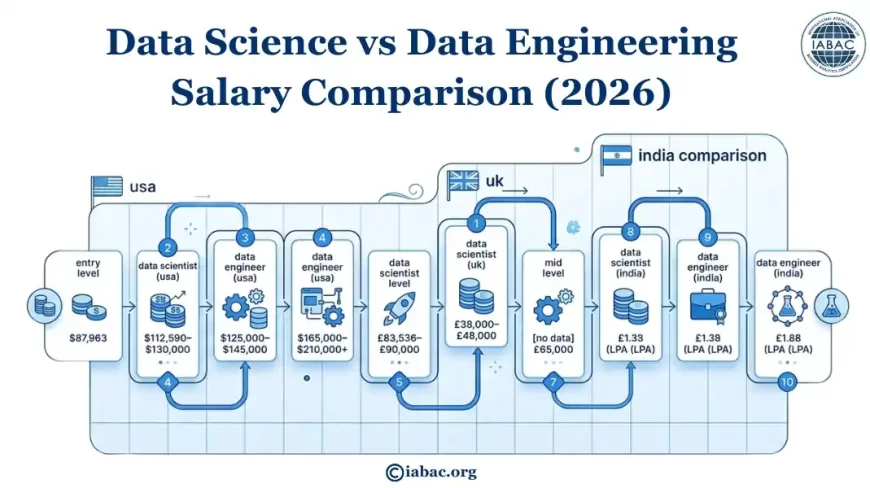
Sources: Glassdoor, Indeed, Talent.com, Levels.fyi, AmbitionBox, and industry salary reports (2025–2026).
An important note: certified professionals earn 30–40% more than their non-certified counterparts on average, according to a study cited by Forbes and referenced by IABAC's own credential documentation. Certification is not just a resume line — it measurably affects compensation.
What You Need to Learn for Data Science vs Data Engineering
The Data Science Syllabus in Full
A complete data science syllabus in 2026 covers the following domains. This is not a casual weekend list — it is a structured learning path that serious practitioners and certification bodies use as a benchmark.
Mathematics and Statistics (Foundation) This is non-negotiable. You need linear algebra (matrix operations, eigenvalues, dot products — these are the backbone of every neural network and dimensionality reduction technique). You need calculus (gradient descent, the optimisation method that trains essentially every machine learning model, is applied calculus). You need probability theory (Bayes' theorem, distributions, expected value) and hypothesis testing (p-values, confidence intervals, A/B testing frameworks).
A simple example: Logistic regression, one of the most widely deployed models in production systems, minimises the following cross-entropy loss function using gradient descent:
L(θ) = -1/n * Σ [yᵢ log(ŷᵢ) + (1 - yᵢ) log(1 - ŷᵢ)]Where:
yᵢ = actual label (0 or 1)
ŷᵢ = predicted probability from the sigmoid function σ(θᵀx)
θ = model weights updated via gradient descent
n = number of training samples
Understanding why this formula works — and what happens when your data is imbalanced or your features are on different scales — separates a practitioner who can build a model from one who knows how to fix it when it breaks in production.
Programming Python is the dominant language, appearing in 51–57% of data science job postings globally (Qualify Nation, citing multiple sources, 2026). The essential libraries: NumPy (numerical computation), Pandas (data manipulation), Matplotlib and Seaborn (visualisation), scikit-learn (classical machine learning), PyTorch or TensorFlow (deep learning).
Machine Learning Supervised learning (regression, classification), unsupervised learning (clustering, dimensionality reduction), ensemble methods (Random Forest, XGBoost, LightGBM), neural networks, model evaluation (confusion matrix, AUC-ROC, F1-score, RMSE), feature engineering, and overfitting prevention (regularisation, cross-validation).
Data Wrangling and EDA The unsexy truth: most of a data scientist's time is spent here. Handling null values, detecting outliers, merging datasets from incompatible schemas, parsing dates stored as strings — this is the real work before the glamorous model training begins.
Communication and Visualisation A model that cannot be explained to a business stakeholder is a model that will not be deployed. Data scientists must tell stories with data — using Tableau, Power BI, or even well-constructed Python plots — and translate statistical findings into business language.
Domain Knowledge A data scientist working in healthcare needs to understand clinical workflows. One working in finance needs to understand risk and regulation. This domain overlay is what separates a hired consultant from a trusted team member.
The Data Engineering Skill Stack in Full
Data engineering sits closer to software engineering than statistics. The knowledge base is wide, tools-heavy, and infrastructure-first.
SQL at Production Scale Not SELECT FROM table — we are talking window functions, query plan optimisation, partitioning strategies, and managing tables with billions of rows across distributed systems.
Programming: Python and JVM Languages Python for scripting, pipeline orchestration, and data transformation. Java or Scala for Apache Spark jobs in large-scale distributed environments. According to the 365 Data Science 2026 job posting analysis, Python appears in 70% of data engineer postings and Java in 32%.
Big Data Frameworks Apache Spark (distributed batch and streaming processing), Apache Kafka (event streaming and real-time data ingestion), Apache Flink (stateful stream processing), and Hadoop (now largely replaced by modern cloud equivalents but still present in legacy environments).
Cloud Platforms AWS (S3, Glue, Redshift, Lambda, EMR), Google Cloud Platform (BigQuery, Dataflow, Pub/Sub, Vertex AI), and Microsoft Azure (Data Factory, Synapse Analytics, Event Hubs). Cloud is not optional in 2026 — it is the default environment for modern data infrastructure.
Workflow Orchestration Apache Airflow (the industry standard), Prefect, and Dagster manage the scheduling, dependency tracking, and failure handling of complex data pipelines. A missed pipeline run does not just cause a gap in a chart — it can mean hours of missing transaction data for a financial institution.
Modern Data Stack dbt (data build tool) for transformation and testing, Fivetran or Airbyte for ingestion, Snowflake or Databricks for the data warehouse or lakehouse layer. This stack has become the standard for mid-to-large data organisations globally.
Data Quality and Governance Great Expectations, Monte Carlo, or custom data quality frameworks. In 2026, regulatory requirements around data governance — GDPR in Europe, the DPDP Act in India, CCPA in the United States — have made data quality monitoring a core engineering responsibility, not an afterthought.
DevOps and Infrastructure Git, CI/CD pipelines for data code, Docker for containerisation, and Kubernetes for orchestrating containerised workloads. Senior data engineers are increasingly expected to manage infrastructure-as-code using Terraform.
Side-by-Side Comparison: Data Scientist vs Data Engineer
|
Dimension |
Data Scientist |
Data Engineer |
|
Primary Goal |
Extract insights, build predictive models |
Build and maintain data infrastructure |
|
Core Languages |
Python, R, SQL |
Python, SQL, Java/Scala |
|
Key Frameworks |
scikit-learn, PyTorch, XGBoost |
Spark, Kafka, Airflow, dbt |
|
Math Requirement |
High — statistics, linear algebra, calculus |
Moderate — applied mathematics |
|
Software Engineering Depth |
Moderate |
High — closer to software engineering |
|
Output |
Models, dashboards, insights, |
Pipelines, databases, data products |
|
Job Growth (2024–2034) |
34% (BLS, 2025) |
Outpacing DS in team share (Indeed, 2026) |
|
Median Salary (USA, 2025) |
$112,590 (BLS, 2025) |
~$130,000 (Glassdoor via 365 DS, 2026) |
|
Typical Entry Point |
Statistics, mathematics, or |
Software engineering or CS background |
|
Closest Analogy |
Detective who reads the clues in data |
Architect who builds the building data lives in |
Why Data Engineering Is Booming Specifically in 2026
Three forces have converged to accelerate data engineering demand above almost every other technical role:
1. The AI Infrastructure Deficit Companies spent 2021–2024 building AI and ML capabilities at the model layer. They hired data scientists, bought MLOps tools, and launched "AI transformation" programmes. Then they discovered their underlying data pipelines were broken, inconsistent, and incapable of supporting production-grade AI systems. The correction: urgent investment in data engineering. Enterprise technology reports indicate that 80% of enterprise analytics operations depend on stable data engineering ecosystems to support business intelligence and AI-driven initiatives (DigitalDefynd, citing Gartner and McKinsey, 2026).
2. Real-Time Data Requirements AI systems in 2026 — recommendation engines, fraud detection systems, dynamic pricing models — need data in milliseconds, not hours. Building streaming architectures with Kafka, Flink, and real-time feature stores is a specialised data engineering discipline that commands significant premium compensation.
3. Regulatory Compliance GDPR enforcement, India's Digital Personal Data Protection Act, and US state-level privacy laws have created legal obligations around data lineage, retention, and quality that fall squarely on data engineers. Compliance-driven infrastructure investment has added an entirely new dimension to the role.
The composition shift in numbers: In 2021, roughly 40% of data professionals identified primarily as data engineers. By 2026, that figure has risen to 55% (Indeed Hiring Lab, 2026). The centre of gravity in data teams has moved toward infrastructure.
Why Data Science Is Still the More Recognised Career Brand
Despite the engineering surge, data science holds significant advantages that matter for global career positioning:
- Volume of roles: With 245,900 US jobs in 2024 growing to a projected 328,300 by 2034 (BLS, 2025), the absolute number of data science openings remains larger than dedicated data engineering postings in most markets.
- Cross-industry presence: Data science roles exist in healthcare (diagnostic modelling, patient outcome prediction), finance (credit scoring, fraud detection, market modelling), retail (demand forecasting, recommendation systems), and government (policy evaluation, resource optimisation). The role has penetrated virtually every sector of the global economy.
- Certification ecosystem maturity: The data science certification pathway is well-established, with globally recognised credentialing frameworks that data engineering has not yet fully developed. This matters for professionals building credentials in markets where institutional recognition carries weight.
- Research and academia pipeline: Data science maintains a strong connection to academic research through machine learning and statistics communities. For professionals interested in contributing to the field at a foundational level, data science offers paths that data engineering does not.
The IABAC Certifications: Your Structured Entry Point
Regardless of which path you choose, the single most consistent piece of advice from hiring managers, recruiters, and senior practitioners in 2026 is this: structured learning with verified credentials opens doors that self-study alone does not.
IABAC — the International Association of Business Analytics Certifications — is one of the most globally recognised credentialing bodies in data science and analytics. The IABAC Certified Data Scientist (CDS) certification has been earned by more than 30,000 professionals and follows the EDISON European Commission framework, ensuring that skills align with what the industry actually needs. The programme covers statistics, big data, programming, machine learning, and advanced data analysis — the full data science syllabus required for mid-to-senior level roles globally. IABAC operates on the principles of the Edison Data Science Framework — a project initiated by the European Commission — making its certifications internationally credible for corporates and professionals alike.
Here is a breakdown of the IABAC certification stack relevant to both paths:
For Aspiring Data Scientists
IABAC Data Science Foundation The IABAC Data Science Foundation course covers important topics like statistics, machine learning, an introduction to data science, the different roles in the industry, and how data science is used in real-world situations. It is ideal for career switchers, graduates, IT professionals, and business analysts building into data roles. This is the starting block for the formal data science roadmap.
IABAC Certified Data Scientist (CDS) The flagship credential. The CDS exam requires candidates to submit a case-study project along with a predictive ML model and project report graded across three areas: Project Summary with recommendations, Machine Learning model performance, and Exploratory Data Analysis. This is not a multiple-choice exam designed for memorisation — it is a practical, project-based assessment that mirrors real-world data science work. Domain-Specific Data Science Certifications IABAC offers data science certifications tailored to specific industries including HR, marketing, and operations — helping professionals use data science in domain-specific contexts where they already have subject matter expertise. A marketing professional who can combine domain knowledge with certified data science skills is significantly more valuable than either skill set alone.
For Aspiring Data Engineers
IABAC's Data Engineering certification pathway helps professionals build skills to make data clean, organised, and ready to use — helping businesses get the most value from their data assets. For professionals entering or transitioning into data engineering, this credential combined with cloud vendor certifications (AWS Certified Data Engineer, Google Professional Data Engineer) creates a strong dual-credential profile.
Why IABAC Credentials Matter in 2026
IABAC certification provides global recognition of relevant skills, thereby opening opportunities across the world, and the CPD (Continuing Professional Development) program enables credential holders to update their skills and stay relevant to industry requirements. In a job market where remote work has made the talent pool genuinely global, a credential recognised across North America, Europe, the Middle East, Southeast Asia, and Africa is worth significantly more than a regional or platform-specific certificate. On average, a certified professional earns 30–40% more than their non-certified counterpart, per a recent Forbes study cited in IABAC's credential documentation. You can explore all current IABAC certifications, from foundation-level to advanced, at https://iabac.org/certifications.
For the full data science certification offering, visit https://iabac.org/data-science-certification.
For the IABAC blog — which covers everything from the latest industry tools to career guides and certification pathways — visit https://iabac.org/blog.
The Full Data Science Roadmap for 2026: Month by Month
Whether you are starting from scratch or pivoting from another technical field, here is a realistic, structured roadmap. No fluff, no vague milestones — just a practical sequence.
Months 1–2: Programming and Data Foundations Learn Python from basics to Pandas and NumPy proficiency. Practice SQL on real datasets (Mode Analytics, SQLZoo, or LeetCode SQL). Complete three exploratory data analysis projects on public datasets (Kaggle is the best source). Get comfortable with Jupyter notebooks and Git.
Months 3–4: Statistics and Classical Machine Learning Study probability distributions, hypothesis testing, and regression analysis. Learn linear regression, logistic regression, decision trees, and random forests using scikit-learn. Build and evaluate a classification model end-to-end on a structured dataset.
Months 5–6: Intermediate Machine Learning and Model Evaluation Study gradient boosting (XGBoost, LightGBM). Learn model evaluation rigorously: confusion matrix, precision-recall tradeoff, AUC-ROC, cross-validation. Build a project on an imbalanced dataset (fraud detection, disease prediction) and document your handling of class imbalance explicitly.
Months 7–8: Deep Learning and Specialisation Introduction to neural networks with PyTorch or TensorFlow. Choose a specialisation: NLP (text classification, transformers), computer vision (image classification, object detection), or time series forecasting. Build one project in your chosen domain.
Months 9–10: Deployment and the End-to-End Pipeline Learn to deploy a machine learning model using FastAPI or Streamlit. Deploy to a cloud service (AWS SageMaker, Google Vertex AI, or Heroku). Understand MLOps basics: model versioning, monitoring for drift, retraining pipelines. A model you cannot deploy is a model that creates no value.
Months 11–12: Certification and Portfolio Completion This is the time to formalise your learning with a globally recognised credential. As an experienced IABAC professional notes: Data Science Certifications validate skills, help professionals stand out in a competitive market, and provide a clear learning path for gaining the practical knowledge required to solve real-world problems.
Complete the IABAC Certified Data Scientist (CDS) programme through an authorised training partner. IABAC has a worldwide network of authorised training partners who offer courses following the IABAC program syllabus, and IABAC members gain exclusive access to seminars and Data Science summits organised by IABAC partners across the globe. Finalise your GitHub portfolio with three to five polished projects. Each should have a clear README, documented methodology, and a section on business impact. Apply, network deliberately, and prepare for technical interviews with LeetCode (Python and SQL) and project walkthroughs.
How to Choose Between Data Science vs Data Engineering
Here is the real question to ask yourself, more useful than any comparison table:
At the end of a long day of work, what kind of problem do you want to have solved?
If the answer is "I figured out why this pattern exists in the data, and now the business will do something different because of it" — you want data science.
If the answer is "I built something that reliably moves millions of records per hour without breaking, and next week it will handle ten times the load without me having to touch it" — you want data engineering.
Both are satisfying. Both are in demand. Both pay well. The difference is in what makes you feel like your day mattered.
Choose Data Science if you:
- Love mathematical reasoning and statistical thinking
- Enjoy translating complex findings into business language
- Want to work at the intersection of machine learning and domain knowledge
- Find model building and evaluation genuinely interesting
- Are drawn to research, experimentation, and iterative improvement
Choose Data Engineering if you:
- Are energised by building systems that are reliable and scalable
- Have a software engineering background and want to stay close to infrastructure
- Enjoy the challenge of making complex data flows work seamlessly
- Are drawn to cloud architecture, distributed systems, and performance optimisation
- Want your work to be the foundation that enables everyone else on the data team
A third option worth noting: The Analytics Engineer role — combining dbt transformation skills, data modelling, and analytical thinking — is growing rapidly as a bridge between the two paths and can be a natural first step for those who are genuinely torn.
The Career Insight Most People Miss About Data Science vs Data Engineering
Here is something that the data from 2026 makes undeniably clear: the boundary between data science and data engineering is actively dissolving at the senior level.
Modern ML platforms — Databricks, Vertex AI, AWS SageMaker — are building features that allow data scientists to manage pipeline orchestration. Feature stores (Feast, Tecton, Vertex AI Feature Store) require data engineers to understand machine learning feature engineering. MLOps — the practice of deploying, monitoring, and maintaining ML models in production — demands fluency in both domains.
The professionals commanding the highest salaries and the most interesting roles in 2026 are not necessarily experts in both fields, but they are conversant in both. A data scientist who understands how a Spark job works and can write a basic Airflow DAG is meaningfully more hireable than one who cannot. A data engineer who understands model drift, feature pipelines, and training data quality is significantly more valuable to an ML-first company than one who only thinks about infrastructure uptime. This cross-domain literacy is precisely why starting with a structured data science certification — one that covers the full lifecycle from raw data to model to deployment — is valuable even for professionals who ultimately intend to specialise in engineering. The conceptual foundations of machine learning make you a better data engineer. The pipelines you build as a data engineer make you a more practical data scientist.
Understanding the whole picture of data to data — from ingestion to insight — is what separates the good from the genuinely excellent.
Why Both Data Science vs Data Engineering Can Lead to a Successful Career
There is no single right answer in the data science vs data engineering debate. The best choice depends on your interests, strengths, and the kind of work you enjoy.
The good news is that both careers are growing fast. Companies across industries need skilled data professionals to manage, analyze, and use data for better decisions. Whether you choose data science or data engineering, the opportunities are strong.
The key to success is not just learning the skills—it is applying them through real projects and earning certifications that employers recognize. IABAC offers certifications for every stage of your journey, from the Data Science Foundation for beginners to the Certified Data Scientist for experienced professionals. Based on the EDISON European Commission framework, these certifications are designed to match the skills employers expect in today's data industry. Start with the basics, build practical projects, earn the right certification, and keep learning. Whether you become a data scientist or a data engineer, you will be building valuable skills that are in demand around the world.












