




























































What Are Common Data Scientist Interview Questions
Explore common data scientist interview questions and learn how understanding data science marketing can boost your job prospects. Get prepared for success.

Getting a job as a Data Scientist can be both exciting and tough. With more companies relying on data for decisions, skilled data scientists are in high demand. To be prepared for interviews, it's important to know the common questions you might face. In interviews, you may be asked about basic data science concepts. These questions will test your knowledge of statistics, programming languages, and how you handle data. You might also be given scenarios to show how you apply your data science skills in realworld situations. If you have certifications like Certified Data Science Developer, Certified Machine Learning Expert, or Certified Data Scientist, be ready for questions about these credentials. They show your deep understanding of data science principles and advanced methods. For those aiming for management roles, expect questions about being a Data Science Certified Manager. These will focus on your ability to lead and manage data science projects. Preparing for these topics will help you feel more confident and ready for your interview.
Top 10 Common Data Scientist Interview Questions and How to Answer Them
Preparing for a data scientist interview can be daunting due to the wide range of topics that might come up. Here are ten common data scientist interview questions and simple tips on how to answer them:
1. What is Data Science?
Data science involves using statistics, machine learning, and data visualization to analyze and interpret data. This question checks if you understand the basics and how data science can be applied to solve problems.
2. Can You Explain the Difference Between Supervised and Unsupervised Learning?
Supervised learning involves training models on data with labels, while unsupervised learning works with data without labels to find patterns. This question tests your understanding of different machine learning methods and their uses.

3. How Do You Handle Missing Data?
When data is missing, you might fill in the gaps, remove incomplete entries, or use techniques that manage missing values. Your answer should show you know how to handle incomplete data effectively.
Here's a concise overview of handling missing data:
1. Removing Incomplete Entries: When the amount of missing data is minimal and doesn’t significantly impact the dataset, you might choose to remove entries with missing values.
Example: Suppose you have a dataset of customer reviews with fields for Customer ID, Rating, and Comment. If only 5% of the reviews have missing Rating values, you might decide to drop those rows to ensure the analysis is based on complete data.
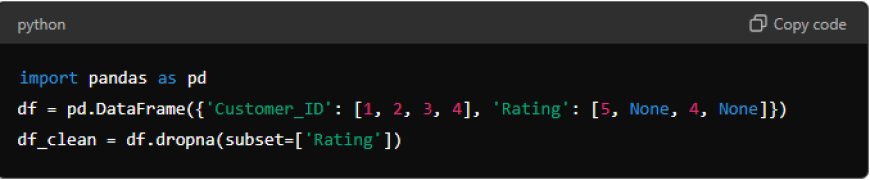
2.Filling in Missing Data: You can impute missing values using statistical methods like mean, median, or mode, or more complex methods like predictive modeling.
Example: Using the same customer review dataset, if the Rating is missing, you could fill in these missing values with the mean rating.

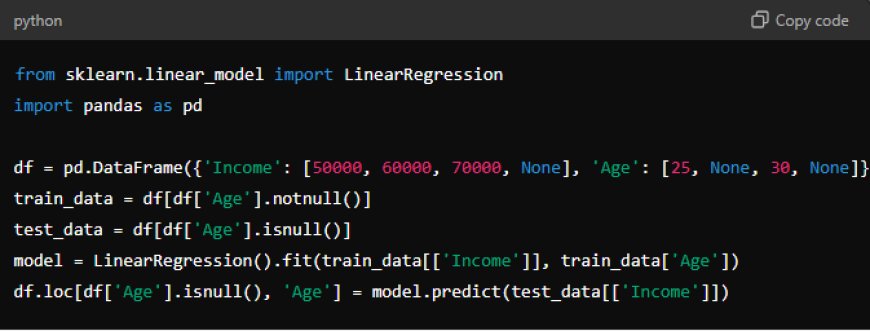
3.Using Predictive Models: For more complex datasets, you can use machine learning models to predict missing values based on other features.
Example: In a dataset where customer age is missing but can be predicted based on other features like income and location, you might use regression to estimate the missing values.
4. What Are Some Common Metrics for Evaluating Machine Learning Models?
Metrics such as accuracy, precision, recall, F1score, and ROCAUC help measure how well a model performs. Discussing these metrics shows you understand how to assess and choose the right model.
(A) Accuracy
-
Definition: Accuracy shows how often the model correctly identifies emails as spam or not spam.

-
Use Case: Accuracy is helpful when the spam and notspam emails are about the same number. It tells you that 80% of the emails were correctly classified.
(B) Precision
-
Definition: Precision measures how many of the emails your model labeled as spam are actually spam.

-
Use Case: Precision is important when wrongly marking a legitimate email as spam is a problem. It helps reduce such mistakes.
(C) Recall
-
Definition: Recall shows how many of the actual spam emails were correctly identified by your model.

-
Use Case: Recall is crucial if missing a spam email could lead to serious issues. It measures how well the model finds all the spam emails.
(D) F1Score
-
Definition: The F1score combines precision and recall into one number to balance both.
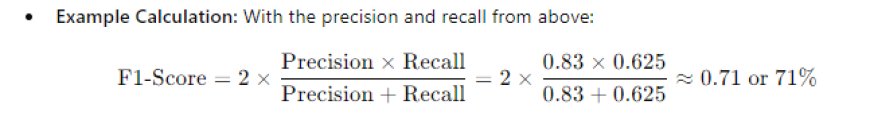
-
Use Case: The F1score is helpful when you need a balance between precision and recall, especially if both are important.
(E) ROCAUC
-
Definition: ROCAUC measures how well the model can tell the difference between spam and not spam across different settings.
-
Example Calculation: If your model’s ROCAUC score is 0.85, it means there’s an 85% chance it can correctly distinguish between spam and not spam.
-
Use Case: ROCAUC is useful for understanding how well the model performs, especially when the number of spam and notspam emails is uneven.
5. What Are Feature Engineering and Feature Selection?
Feature engineering and feature selection are key steps in improving machine learning models by refining the data used for training.
- Feature Engineering Feature engineering transforms raw data into useful inputs that improve model accuracy. Some common tasks include:
- Handling missing data
- Encoding categories (like one-hot encoding)
- Scaling and normalizing data
- Creating new features by combining existing ones
- Dealing with outliers
Good feature engineering helps the model find patterns and improve performance.
- Feature Selection Feature selection involves picking the most important features to simplify the model and avoid overfitting. Common methods include:
- Filter methods (e.g., correlation analysis)
- Wrapper methods (e.g., forward selection)
- Embedded methods (e.g., Lasso regression)
It helps reduce complexity, making models faster and more effective.
- The Difference
- Feature Engineering: Creates new features from raw data.
- Feature Selection: Chooses the most important features for the model.
Both processes are essential for improving machine learning performance.
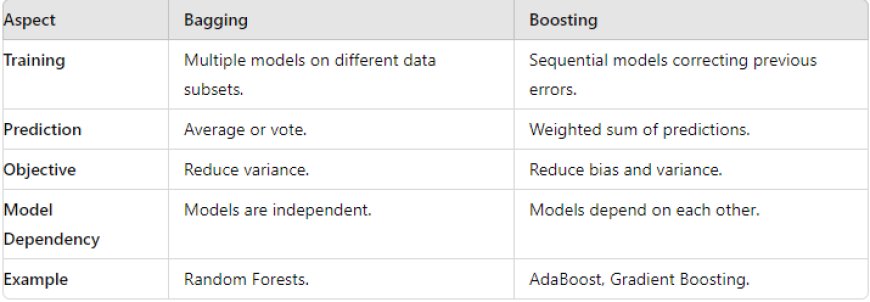
6. What’s the difference between bagging and boosting?
-
Answer: Bagging (Bootstrap Aggregating) trains multiple models on different subsets of data and averages their results. Boosting trains models sequentially to correct errors made by previous models, improving accuracy.
7.What are some differences between SQL and NoSQL databases?
Answer: SQL databases are relational and use structured query language for structured data with a fixed schema. NoSQL databases are nonrelational, handle unstructured or semistructured data, and offer more flexibility and scalability.

8.What is the difference between L1 and L2 regularization?
-
L1 Regularization (Lasso): Adds the absolute values of coefficients, promoting sparsity (some coefficients become zero).
-
L2 Regularization (Ridge): Adds the squared values of coefficients, reducing the impact of large coefficients but not making them zero.
9.What does a data scientist do in a business setting?
A data scientist analyzes data to provide insights that help businesses make better decisions. They use statistical methods, machine learning, and data visualization to solve business problems.
10.What does a data scientist do in a business setting?
A data scientist analyzes data to provide insights that help businesses make better decisions. They use statistical methods, machine learning, and data visualization to solve business problems.
Data scientist interviews often focus on your technical skills, problem-solving abilities, and communication. To succeed, get familiar with common questions and practice your answers. This way, you can show off your expertise and improve your chances of doing well.












