





























































Reinforcement Learning
Learn about Reinforcement Learning, a machine learning approach where agents learn optimal actions through rewards and penalties in dynamic environments.

Reinforcement Learning (RL) is an exciting part of artificial intelligence (AI), which I have been learning about for a while. It helps machines make decisions by learning from their experiences, just like people and animals do. Unlike other types of machine learning that need labeled data, RL works through trial and error, using rewards and penalties to improve over time.
Machine learning has three main types: Supervised, Unsupervised, and Reinforcement Learning.
-
Supervised Learning: The model learns from labeled data, meaning it already knows the correct answers. It is commonly used in tasks like image recognition and speech processing.
-
Unsupervised Learning: The model finds patterns in data without any labels. It is useful for clustering similar items or detecting anomalies.
-
Reinforcement Learning: The model learns by interacting with an environment and receiving feedback in the form of rewards and penalties.
Reinforcement Learning (RL) is changing industries like gaming, robotics, healthcare, and finance. Here’s what I’ve learned about how it works, its uses, challenges, and future.
What is Reinforcement Learning?
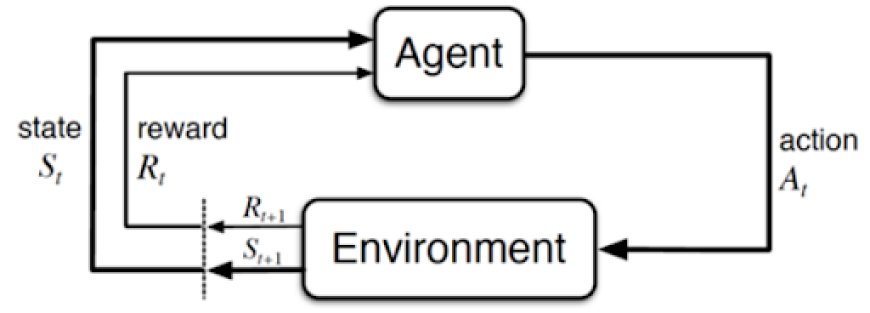
Reinforcement Learning is a type of machine learning where an agent interacts with an environment to achieve a goal. The agent takes action, receives feedback in the form of rewards or penalties, and gradually learns the best way to maximize cumulative rewards over time.
I like to think of RL as training a dog. When you teach a dog to sit, you reward it with a treat when it does the right action. Over time, the dog learns that sitting when commanded results in a positive outcome. Similarly, RL agents learn through positive and negative feedback.
Key Components of RL
-
Agent: The entity that makes decisions.
-
Environment: The system with which the agent interacts.
-
State (S): A representation of the environment at a given time.
-
Action (A): Choices available to the agent.
-
Reward (R): Feedback that guides learning.
-
Policy (π): The agent’s strategy for selecting actions.
-
Value Function (V): The expected long-term reward from a given state.
-
Q-Value (Q-function): The expected reward for taking a specific action in a state.
Understanding these elements helped me appreciate how RL models learn to make decisions.
The Mathematics Behind RL
At first, I found the mathematical aspect of RL intimidating, but breaking it down helped me grasp its significance. RL is fundamentally based on Markov Decision Processes (MDPs), which model decision-making in an environment.
An MDP consists of:
-
States (S): Possible situations the agent can be in.
-
Actions (A): Choices the agent can make.
-
Transition Probability (P): The probability of moving from one state to another.
-
Reward Function (R): The immediate benefit of taking an action.
-
Discount Factor (γ): A value between 0 and 1 that determines the importance of future rewards.
Bellman Equation
One of the most important formulas in RL is the Bellman Equation, which helps compute the value function:
This equation essentially states that the value of a state is the immediate reward plus the discounted value of future states.
Types of RL Algorithms
As I progressed in my RL journey, I discovered that there are three main categories of RL algorithms:
1. Value-Based RL
-
Focuses on learning a value function to estimate the best action.
-
Example: Q-Learning and Deep Q-Networks (DQN).
-
Used in games like Atari and self-driving simulations.
2. Policy-Based RL
-
Directly learns a policy instead of a value function.
-
Example: Policy Gradient Methods (REINFORCE, PPO).
-
Useful for problems with continuous action spaces, such as robotic control.
3. Actor-Critic RL
-
Combines both value-based and policy-based approaches.
-
Examples: Advantage Actor-Critic (A2C), Proximal Policy Optimization (PPO), Deep Deterministic Policy Gradient (DDPG).
-
Efficient for real-world applications requiring both stability and exploration.
I realized that selecting the right RL algorithm depends on the complexity of the problem and the nature of the environment.
Popular RL Algorithms
1. Q-Learning
Q-Learning is one of the first RL algorithms I experimented with. It maintains a Q-table, which stores the expected rewards for each state-action pair. The Q-values are updated using the Bellman Equation:
Q(s,a)=Q(s,a)+α[R+γmaxQ(s′,a′)−Q(s,a)]Q(s, a) = Q(s, a) + \alpha [R + \gamma \max Q(s', a') - Q(s, a)]
where:
-
Q(s,a)Q(s, a) is the current Q-value.
-
α\alpha is the learning rate.
-
RR is the reward received.
-
γ\gamma is the discount factor.
-
maxQ(s′,a′)\max Q(s', a') is the highest Q-value for the next state.
However, Q-Learning struggles in large state spaces, which is where Deep RL comes in.
2. Deep Q-Networks (DQN)
Deep Q-Networks (DQN) use deep neural networks to approximate the Q-function, solving high-dimensional problems such as video games. Key innovations include:
-
Experience Replay: Stores past experiences and reuses them for training to improve stability and efficiency.
-
Target Networks: Maintains a separate target network to prevent drastic changes in Q-values and enhance training stability.
The DQN update rule is:
Q(s,a)=R+γmaxa′Q(s′,a′)Q(s, a) = R + \gamma \max_{a'} Q(s', a')
where the Q-value is updated based on the highest estimated reward for the next state.
3. Policy Gradient Methods
Unlike Q-Learning, which focuses on learning a value function, Policy Gradient (PG) methods learn policies directly by optimizing the expected return.
A well-known approach is the REINFORCE algorithm, which updates policies using:
∇J(θ)=E[∇logπθ(a∣s)R]\nabla J(\theta) = \mathbb{E} [ \nabla \log \pi_\theta (a | s) R ]
where:
-
J(θ)J(\theta) is the objective function to maximize rewards.
-
πθ(a∣s)\pi_\theta (a | s) is the probability of taking action aa given state ss.
-
RR is the return received.
Policy Gradient methods are effective in continuous action spaces but can have high variance, requiring optimization techniques like baseline subtraction or variance reduction.
4. Actor-Critic Methods
Actor-Critic (AC) methods combine both value-based and policy-based approaches. They use two neural networks:
-
Actor: Learns the policy πθ(a∣s)\pi_\theta(a | s), deciding which action to take.
-
Critic: Evaluates the action using a value function V(s)V(s), helping the actor make better decisions.
The advantage function is often used to reduce variance:
A(s,a)=Q(s,a)−V(s)A(s, a) = Q(s, a) - V(s)
Popular Actor-Critic methods include:
-
Advantage Actor-Critic (A2C)
-
Proximal Policy Optimization (PPO)
-
Deep Deterministic Policy Gradient (DDPG)
These methods are particularly useful for robotics and real-time control environments.
Real-World Applications of RL
1. Robotics
-
RL helps robots learn to walk, grasp objects, and navigate environments autonomously.
2. Gaming
-
AlphaGo defeated human Go champions using RL.
-
OpenAI Five mastered Dota 2 through multi-agent RL.
3. Finance
-
RL is used for algorithmic trading and portfolio management.
4. Healthcare
-
Personalized treatment plans are optimized using RL.
-
AI-driven drug discovery accelerates research.
5. Self-Driving Cars
-
RL is used for path planning, decision-making, and collision avoidance.
Seeing these applications firsthand made me appreciate the transformative power of RL.

Challenges in RL
While RL is powerful, I encountered several challenges along the way:
-
Sample Inefficiency – RL requires a large number of interactions with the environment.
-
Reward Design – Poorly designed rewards can lead to unintended behaviors.
-
Exploration vs. Exploitation – Balancing between trying new strategies and refining existing ones.
-
Training Stability – Deep RL models are prone to instability.
-
Generalization – RL models trained in one environment may fail in another.
These challenges are areas of active research, and new solutions are constantly emerging.
The Future of Reinforcement Learning
The future of RL is promising. Recent advancements include:
-
Meta-Reinforcement Learning – AI learning how to learn.
-
Hierarchical RL – Breaking tasks into subtasks for better decision-making.
-
Multi-Agent RL – Collaboration between multiple RL agents.
-
Offline RL – Learning from previously collected data without further exploration.
I believe RL will continue to evolve, pushing AI beyond what we currently imagine.
My journey into Reinforcement Learning has been eye-opening. From simple Q-learning algorithms to complex actor-critic models, RL has reshaped the way I view AI decision-making. While challenges remain, the potential applications of RL make it an exciting field to watch. As I continue exploring RL, I look forward to seeing how it shapes the future of technology.
If you’re interested in RL, I highly recommend diving in and experimenting with RL frameworks like OpenAI Gym, TensorFlow RL, and Stable-Baselines. The best way to learn is by doing!
If you want to learn more Refer to this:- Machine Learning Roadmap












