




























































The One Algorithm Behind All AI: How Machines Learn
Learn how one algorithm drives AI systems, showing how machines learn from data through iterative training, pattern discovery and model optimization.

Backpropagation is one of the most crucial algorithms in machine learning. It powers training processes behind models like GPT, AlphaFold, and Midjourney. Despite the differences in architecture and purpose among these systems, backpropagation is the thread that ties them together. Understanding it, especially from the ground up, provides deep insight into how artificial systems learn and improve over time.
Why Backpropagation Matters
Almost every machine learning model trains by improving its performance on a specific task through optimisation. This optimization is driven by minimizing an error metric, or loss, which measures how far off the model's predictions are from the expected results.
At the core of this process is backpropagation—a method to compute how each model parameter (like a weight in a neural network) affects the overall loss. Without backpropagation, efficient training of modern AI systems wouldn’t be feasible.

Backpropagation: Not How the Brain Learns
While backpropagation is essential to artificial intelligence learning, it’s not how biological brains operate. The mechanisms behind synaptic plasticity in the brain are still being researched, and although some biological processes resemble gradient-like behaviour, direct equivalents to backpropagation don’t exist in the human brain.
This key difference underscores the divergence between artificial and biological intelligence and frames the motivation for studying alternative learning algorithms that might mimic how the brain functions.
Building Intuition Through Curve Fitting
To understand backpropagation, consider a simpler problem: fitting a curve to a set of points on a graph. This is a classical regression task, where we attempt to approximate the relationship between inputs (x) and outputs (y) using a mathematical function.
Let’s assume we want to fit a polynomial of degree five to the data. This means our function looks like:
y(x) = k₀ + k₁x + k₂x² + k₃x³ + k₄x⁴ + k₅x⁵
The goal is to find the set of coefficients (k₀ to k₅) that results in the curve that best fits the data.
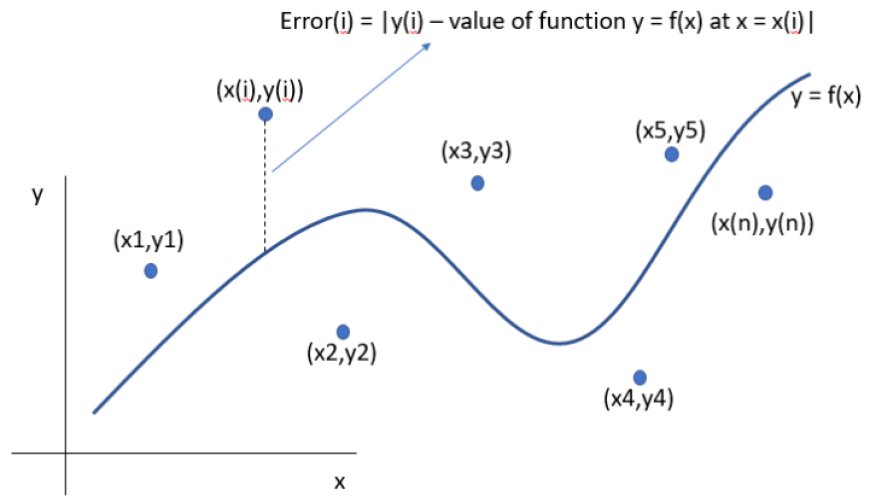
Defining “Best Fit”: Introducing the Loss Function
To determine how good a particular curve is, we use a loss function—a numerical value that tells us how far off the curve is from the actual data points. A common choice is the total squared distance between the points and the curve. Mathematically, it measures the sum of squared errors between predicted values and actual outputs.
This loss depends on the coefficients k₀ through k₅. So, we can write the loss as a function:
L(k₀, ..., k₅)
Our objective becomes minimizing this function. In machine learning, this process of reducing the loss by tweaking the model parameters is the essence of training.
The Problem: How Do We Minimize the Loss?
Suppose we have a machine (call it "Curve Fitter 6000") with six knobs, each controlling one of the k values. We can try random settings and measure the resulting loss, but this is inefficient and unlikely to find the optimal configuration.
To optimize more efficiently, we need direction—information about how adjusting each knob affects the loss. That’s where the concept of derivatives enters.
From Random Guessing to Gradient Descent
If our loss function is differentiable (which it typically is), we can compute the gradient—a vector of partial derivatives that tells us the direction and rate of change of the loss with respect to each parameter.
This is the idea behind gradient descent: we update each parameter in the direction that most reduces the loss. Formally, this looks like:
kᵢ ← kᵢ - α * ∂L/∂kᵢ
Here, α is the learning rate—a small number that controls how big each step is.
Understanding Derivatives
To understand how gradients help us minimize the loss, it helps to revisit basic calculus. A derivative tells us how a function changes as its input changes. For a single-variable function, the derivative at a point is the slope of the tangent line.
In higher dimensions, each parameter has its own partial derivative, and these together form the gradient vector, which points in the direction of steepest ascent. To reduce the loss, we move in the opposite direction.
The Key Challenge: Calculating the Gradient
For simple functions, derivatives are easy to compute manually. But machine learning models often involve many parameters and layers of nested functions. Manually computing derivatives in such cases is impractical.
The solution lies in automating the process of differentiation using a structure called a computational graph.
The Chain Rule and Computational Graphs
Every computation in a model—be it a multiplication, addition, or activation—can be broken down into a sequence of basic operations. These form a computational graph, where nodes represent operations and edges represent data flow.
To compute gradients in such a graph, we use the chain rule of calculus. This rule tells us how to compute the derivative of a composite function by multiplying the derivatives of its constituent parts.
In backpropagation, we first perform a forward pass to compute the loss. Then we do a backward pass, moving through the graph in reverse and applying the chain rule at each step to compute the gradient of the loss with respect to every parameter.
Backpropagation in Practice
Here’s how backpropagation fits into the training loop:
-
Forward pass: Compute model output and loss for the current parameter values.
-
Backward pass: Use the chain rule to compute gradients of the loss with respect to all parameters.
-
Update step: Adjust parameters using gradient descent.
-
Repeat: Iterate this process until the loss is acceptably low or training stops.
This loop runs for many iterations—sometimes millions—especially for large neural networks. But each iteration brings the model closer to optimal performance.

Extending to Neural Networks
Although we started with a polynomial curve, the same ideas apply to neural networks. In a neural network, each layer performs operations on its inputs using parameters (weights), which can be trained using backpropagation.
The key requirement is that the model be composed of differentiable functions. As long as the operations in each layer (e.g., linear transformations, nonlinear activations) are differentiable, we can apply backpropagation.
This algorithm has proven to be robust, scalable, and adaptable to various architectures, from convolutional networks for image recognition to transformers for natural language processing.
Beyond Backpropagation: What About the Brain?
The blog ends where it began: questioning whether backpropagation is biologically plausible. While powerful in artificial systems, there's limited evidence to suggest that the human brain employs anything like it.
Instead, the brain might rely on different mechanisms such as local synaptic updates, Hebbian learning, or spike-timing-dependent plasticity. These alternatives will be explored in the follow-up content, which delves into biological learning mechanisms.
Backpropagation is not just an algorithm—it’s a framework for learning. Understanding how small changes in parameters affect performance it allows machines to improve through experience. Whether it’s fitting a curve or optimising a deep neural network, backpropagation enables systems to learn complex patterns from data.












