





























































Common Data Science Interview Questions
Preparing for a data science interview? Get familiar with commonly asked questions covering statistics, ML, Python, and business problem-solving.

Preparing for a Data Science interview can be difficult because there are many topics to cover. From coding and statistics to solving real-world problems, interview questions can come from different areas. To feel more confident and prepared, it is important to know what types of questions you may face. In this guide, we will go through some Common data science interview questions and explain them in a simple way. We will also share tips to help you answer them effectively. Whether you are new to Data Science or already have experience, understanding these questions can help you prepare better for your interview. Having a strong Data Science Foundation is important because many interview questions are based on basic concepts such as statistics, data analysis, and machine learning. A Data Science Career Certification can also help you build knowledge and show employers that you have the skills needed for Data Science roles.
Machine learning is an important part of Data Science and is used in many industries. One of its key techniques is classification, which helps computers place data into specific categories. Classification is used in many real-life applications, such as detecting spam emails, recommending products, and supporting medical diagnosis. It helps systems identify patterns in data and make accurate predictions. As machine learning continues to improve, classification remains an important method that helps organizations make better decisions and solve problems more effectively.
Why Data Science Certifications Are Key to Career Success
The need for data science professionals is growing fast as businesses realize how important data is for making smart decisions. Companies in fields like finance, HR, and marketing are looking for skilled data scientists to turn large amounts of data into useful insights. This high demand means that the job market is competitive, and candidates often face tough data science interview questions.
To keep up with industry needs, getting certified can make a big difference. Certifications like Certified Data Scientist - Finance, Certified Data Scientist - HR, and Certified Data Scientist - Marketing are becoming crucial. Advanced roles, such as Data Science Certified Manager, Certified Data Engineer, and Certified MLOps Engineer, are also in high demand. These certifications not only show that a candidate has the right skills but also help them stand out in a crowded job market.
Overcoming the Challenges of Data Science Interviews: How to Handle Tough Questions
Data science interviews can be very tough, often featuring complex problems and scenarios that test your analytical skills. The real challenge isn't just knowing the right answers but being able to clearly explain your thinking. Data science interview questions can cover everything from theoretical concepts to practical case studies, so it's important to prepare in many different areas. Even with solid knowledge, the stress of the interview can make it hard to perform well, especially when faced with tricky or multi-part questions.

Common Data Science Interview Questions and Answers
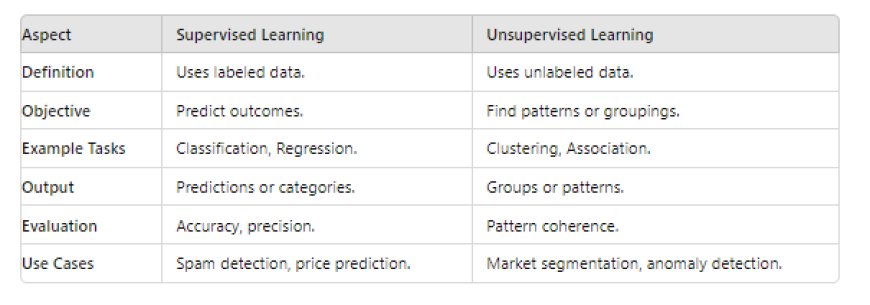
1. What is the difference between supervised and unsupervised learning?
Supervised learning uses labeled data to train models, meaning you provide examples with known outcomes. Unsupervised learning works with unlabeled data, where the model tries to find patterns on its own. For example, predicting house prices based on past data is supervised learning, while grouping customers by their buying habits is unsupervised learning.
2. Can you explain the concept of overfitting and how to prevent it?
Overfitting happens when a model learns too much from the training data, including noise and outliers, which can hurt its performance on new data. To avoid overfitting, use techniques like cross-validation, regularization, or dropout in neural networks to make the model more general.
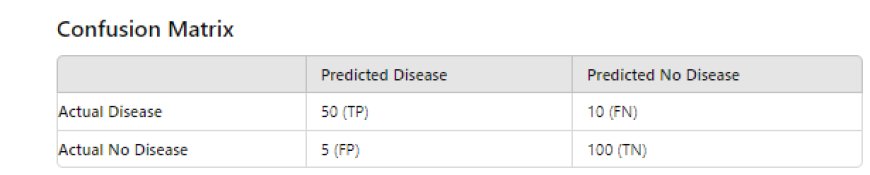
3. What is a confusion matrix, and why is it important?
A confusion matrix helps evaluate how well a classification model works by comparing its predictions with actual results. Here's a quick look:
Example Scenario
Imagine a model that predicts if a patient has a disease:
- True Positives (TP): Correctly predicted "Disease."
- False Positives (FP): Incorrectly predicted "Disease."
- True Negatives (TN): Correctly predicted "No Disease."
- False Negatives (FN): Incorrectly predicted "No Disease."
Key Points
- True Positives (TP): 50 correctly identified as having the disease.
- False Negatives (FN): 10 missed cases of the disease.
- False Positives (FP): 5 incorrect diagnoses of the disease.
- True Negatives (TN): 100 correctly identified as not having the disease.
Why It Matters
- Performance: Shows how well the model works.
- Error Analysis: Helps identify mistakes.
- Metrics: Used to calculate accuracy, precision, recall, and other metrics often discussed in data science interview questions.
4. How do you handle missing data in a dataset?
There are several ways to deal with missing data: you can fill in missing values with the mean, median, or mode, remove rows or columns with missing values, or use algorithms that can handle missing data. For instance, replacing missing values with the median of the column is a common approach.
5. What are feature selection techniques, and why are they used?
Feature selection techniques are used to identify the most important features (variables) for building a predictive model. This process helps in improving model efficiency, reducing complexity, and enhancing performance. Key techniques include:
- Recursive Feature Elimination (RFE): Iteratively removes features and evaluates model performance to select the best subset.
- Feature Importance from Tree-Based Models: Uses models like Random Forests to rank features based on their contribution to the model.
- Statistical Tests: Applies tests (e.g., Chi-square, ANOVA) to evaluate the relationship between features and target variables.
These techniques ensure that only the most relevant features are included, leading to better model accuracy and efficiency.
6. Can you describe a time when you had to deal with a large dataset? How did you manage it?
When working with large datasets, techniques like sampling, distributed computing, or reducing the data size can be useful. For example, using Apache Spark can help process large amounts of data quickly by splitting the work across multiple machines.
7. What is cross-validation, and why is it important?
Cross-validation is a method to check how well a model will perform on new, unseen data. It involves splitting the data into parts, training the model on some of these parts, and testing it on the others. This helps ensure the model doesn’t just perform well on the training data but generalizes well to new data.
8. Explain the concept of bias-variance tradeoff.
The bias-variance tradeoff is about finding a balance between two types of errors. Bias refers to errors from overly simple models, while variance refers to errors from overly complex models. A model with high bias might not capture important patterns (underfitting), while a model with high variance might overfit to the training data.
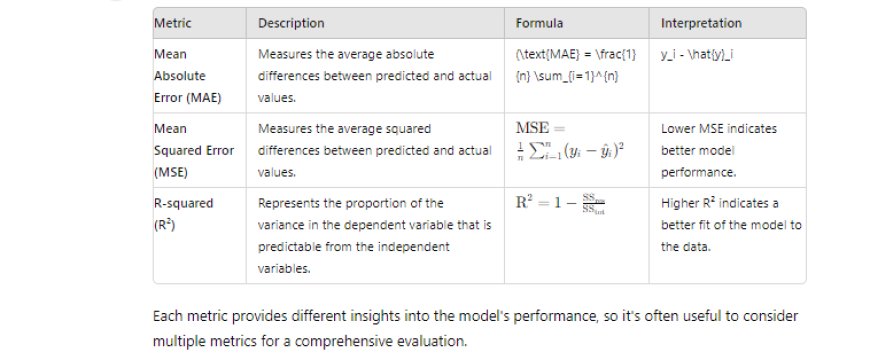
9. How do you evaluate the performance of a regression model?
To evaluate a regression model, use metrics like Mean Absolute Error (MAE), Mean Squared Error (MSE), and R-squared. For example, MSE calculates the average squared difference between predicted and actual values, helping you understand how well the model predicts.
10. What are some common algorithms used in data science, and when would you use them?
Some common algorithms include linear regression, logistic regression, decision trees, random forests, and support vector machines. For example, use linear regression for predicting continuous values and logistic regression for binary classification problems.
How to Prepare for Common Data Science Interview Questions
Preparing for data science interviews might feel daunting, but focusing on a few key areas can help you feel ready:
1. Get the Basics Right
- Core Topics: Make sure you understand essential subjects like statistics, probability, and machine learning.
- Data Skills: Practice using tools like Python, R, or SQL for working with data.
2. Review Important Algorithms
- Machine Learning Models: Learn about models such as linear regression, decision trees, and neural networks.
- Hands-On Practice: Try using tools like TensorFlow and Scikit-learn to implement these models.
3. Practice Problem-Solving
- Coding Exercises: Work on coding problems from platforms like LeetCode.
- Mock Interviews: Practice answering common data science interview questions in mock interviews.
4. Stay Updated
- Current Trends: Keep up with the latest tools and methods in data science.
- Case Studies: Study real-world examples to understand how data science is used.
5. Know the Role
- Role-Specific Skills: Prepare for the specific data science role you’re applying for, whether it’s a Data Science Foundation Certification or a Machine Learning Expert Certification.
- Company Research: Learn about the company's data needs and challenges.
6. Prepare for Behavioral Questions
- Soft Skills: Be ready to talk about your teamwork, problem-solving, and communication abilities.
- STAR Method: Use the STAR method to answer behavioral questions clearly.
By following these strategies, you’ll be well-prepared to handle the data science interview questions that come your way. Whether you're pursuing a Data Science Foundation Certification, Data Science Developer Certification, or another certification, thorough preparation is key to success.












