



























































How Data Scientists Turn Raw Data Into Smart Business Decisions?
Data scientists turn raw data into smart business decisions by analyzing patterns, building models, and generating actionable insights.

Data scientists turn raw data into smart business decisions by collecting, organizing, analyzing, and interpreting information to identify patterns, predict outcomes, and generate actionable insights. Using analytics, statistics, and machine learning, they help businesses improve customer retention, detect fraud, forecast demand, optimize operations, and support faster, evidence-based decision-making.
The process involves preparing raw datasets, identifying meaningful trends, building predictive models, and translating analytical findings into practical recommendations that business teams can apply confidently across different functions and industries.
From raw information to actionable insights, the data science process typically follows this path:
Identify the Business Problem → Collect Raw Data → Clean & Prepare Data → Discover Patterns → Build Predictive Models → Generate Smart Business Decisions
Why Businesses Cannot Use Raw Data Directly
According to IDC,organizations now generate enormous volumes of data daily across apps, transactions, sensors, and digital platforms.
Companies collect enormous amounts of information every day through customer interactions, transactions, mobile apps, sensors, websites, and operational systems. However, raw data alone rarely helps businesses make informed decisions.
Most datasets contain:
-
duplicate records
-
missing values
-
inconsistent formats
-
outdated information
-
disconnected systems
Without proper analysis, businesses may struggle to understand why customers leave, why sales decline, or why operational delays happen.
That is why data scientists play a critical role in organizing, analyzing, and transforming raw information into meaningful insights that support smarter business decisions.
How Data Scientists Turn Raw Data into Smart Business Decisions - Step-by-Step Process
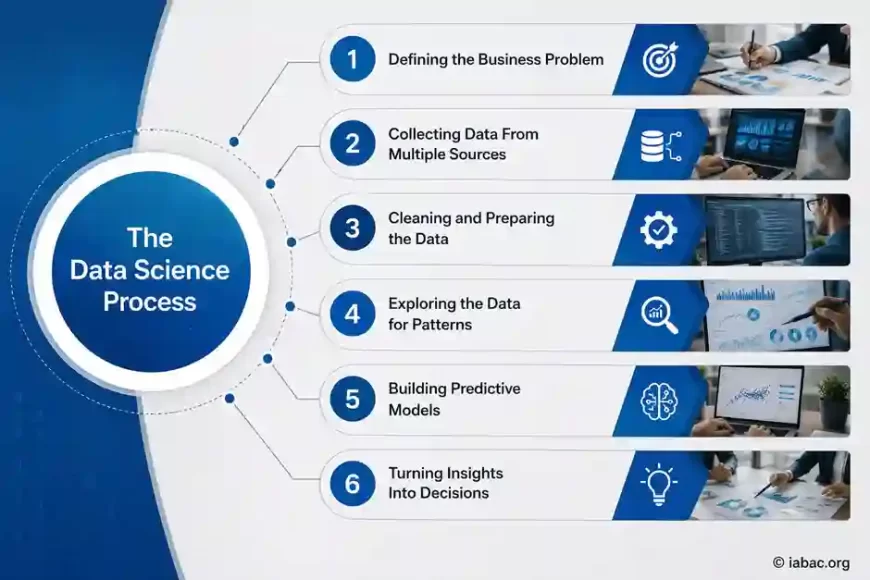
1. Defining the Business Problem
Every successful project starts with the right question.
Poorly framed questions create weak analysis, even with strong data.
A company may ask:
-
Why are customers canceling subscriptions?
-
Which products will perform best next quarter?
-
Which users are likely to default on payments?
-
Why are delivery times increasing in one region?
An experienced data scientist converts broad business concerns into data-driven analytical goals.
For example:
“Why are customers leaving?” becomes:
-
Which customer groups churn most often?
-
At what stage do cancellations happen?
-
Which behaviors appear before churn?
-
What variables correlate strongly with cancellations?
This step shapes the entire direction of the project.
McKinsey reported that data-driven organizations are 23 times more likely to acquire customers and significantly more likely to improve profitability through informed decision-making.
2. Collecting Raw Data From Multiple Sources
Once the problem becomes clear, the next stage involves gathering relevant information.
Data can come from:
-
mobile apps
-
websites
-
CRM systems
-
payment platforms
-
IoT sensors
-
customer surveys
-
APIs
-
cloud databases
A modern data scientist rarely works with one clean dataset.
Instead, information often arrives from multiple departments with inconsistent formatting.
Structured vs Unstructured Data
|
Structured Data |
Unstructured Data |
|
SQL databases |
Emails |
|
Excel sheets |
Videos |
|
Transaction logs |
Images |
|
Sales tables |
Social media posts |
Unstructured information creates additional complexity because machines cannot interpret it easily without preprocessing.
That challenge explains why the data science process demands both technical and analytical skills.
3. Cleaning and Preparing the Data
This stage receives little attention outside the industry, though it consumes the majority of project time.
Anaconda’s State of Data Science report found that data professionals spend a major portion of their workflow preparing and cleaning datasets.
That work includes:
-
removing duplicate entries
-
correcting formatting issues
-
handling missing values
-
detecting anomalies
-
standardizing units
-
validating records
Imagine an e-commerce company analyzing customer age groups.
If age values contain errors, such as:
-
negative numbers
-
blank fields
-
inconsistent formats
The final analysis becomes unreliable.
Poor data quality creates poor business decisions.
Experienced data scientists understand that clean input matters more than sophisticated algorithms.
Why This Stage Matters So Much
A forecasting model trained on inaccurate inventory records may cause:
-
overstocking
-
delayed shipments
-
unnecessary operational costs
The quality of insights depends heavily on the quality of preparation.
4. Exploring the Data for Patterns
After preparation, the next phase focuses on exploration.
This stage is often called Exploratory Data Analysis (EDA).
Here, a data scientist studies:
-
trends
-
anomalies
-
customer behavior
-
seasonal shifts
-
relationships between variables
Visualization tools help reveal patterns hidden inside large datasets.
For instance:
-
Customer purchases may spike during weekends
-
Delivery delays may increase during rainfall
-
Churn may rise after failed payment attempts
Sometimes, exploration changes the original business assumption entirely.
In practice, a telecom company may initially believe pricing causes customer churn. Analysis could reveal that poor support response times create a bigger problem.
That discovery changes the business strategy completely.
Common Tools Used During Exploration
|
Purpose |
Tools |
|
Querying data |
SQL |
|
Analysis |
Python, R |
|
Visualization |
Tableau, Power BI |
|
Statistical exploration |
Pandas, NumPy |
This stage transforms raw data into insights that teams can investigate further.
5. Building Predictive Models
Once patterns emerge, the next step involves prediction.
A data scientist may build machine learning models that estimate:
-
future sales
-
customer churn
-
fraud probability
-
delivery demand
-
product recommendations
Machine learning works by identifying patterns from historical data.
For example:
A payment platform can analyze previous fraudulent transactions and train a model to identify suspicious activity within seconds.
Common Modeling Approaches
|
Model Type |
Business Use |
|
Regression |
Sales forecasting |
|
Classification |
Fraud detection |
|
Clustering |
Customer segmentation |
|
Recommendation systems |
Product suggestions |
Still, strong predictions depend on business relevance.
A technically accurate model that business teams cannot understand often fails during implementation.
That is why communication matters heavily in data science decision-making.
6. Turning Insights Into Decisions
This stage separates useful analysis from forgotten reports.
A data scientist rarely makes final business decisions independently.
Instead, the role supports leaders with evidence-backed recommendations.
For example:
|
Insight |
Business Action |
|
Customers abandon carts after payment failure |
Improve payment gateway reliability |
|
Delivery delays rise during peak hours |
Increase staffing during rush periods |
|
Younger users prefer mobile purchases |
Prioritize mobile-first design |
Clear communication becomes critical here.
A complex chart filled with technical terminology creates confusion.
Strong data scientists explain findings in ways that executives, marketers, and operational teams can understand quickly.
That skill often determines whether insights lead to action.
How Data Scientists Work Across Industries
Data science influences far more than technology companies.
Healthcare
Hospitals use predictive analytics to identify high-risk patients earlier.
By analyzing:
-
medical history
-
vitals
-
readmission patterns
-
treatment outcomes
healthcare teams improve planning and patient monitoring.
Finance
Banks use data science and machine learning for:
-
fraud detection
-
credit scoring
-
risk assessment
-
transaction monitoring
Modern fraud systems evaluate transactions in milliseconds.
Retail and E-Commerce
Recommendation systems analyze:
-
browsing history
-
purchase behavior
-
search activity
-
product interactions
35% of Amazon’s sales come from recommendations, contributing significantly to overall revenue generation.
Logistics
Delivery platforms optimize:
-
route planning
-
estimated arrival times
-
warehouse allocation
-
fuel efficiency
That improves customer satisfaction and operational performance.
Challenges Data Scientists Face Behind the Scenes
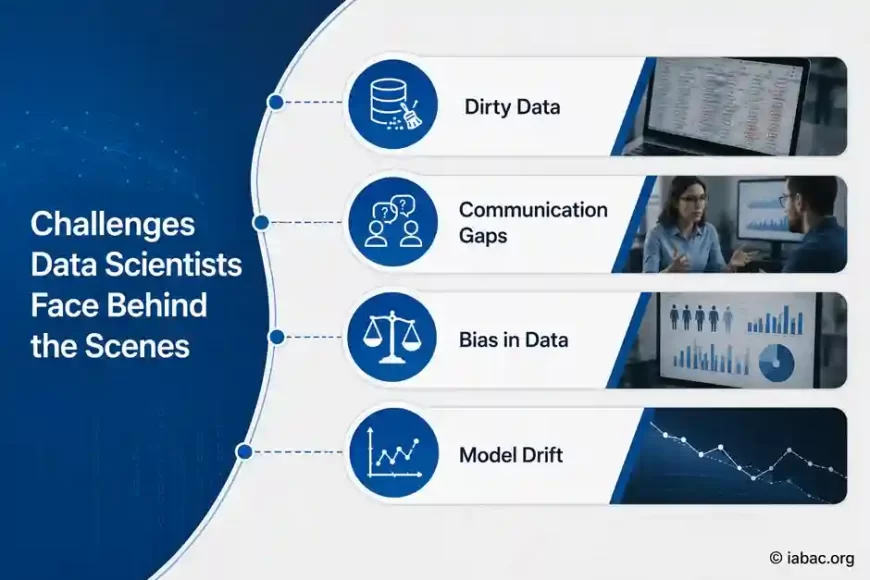
The field sounds exciting from the outside. Daily work includes several difficult realities.
Dirty Data
Messy information remains one of the biggest obstacles.
Different departments may store records in incompatible systems, creating inconsistencies that slow analysis.
Communication Gaps
Technical findings mean little if stakeholders cannot understand them.
Strong communication skills often matter as much as coding ability.
Bias in Data
Biased training data can produce unfair outcomes in:
-
hiring systems
-
lending approvals
-
healthcare recommendations
Ethical evaluation has become a major responsibility for every data scientist.
Model Drift
Customer behavior changes over time.
A model performing well today may become unreliable months later. Continuous monitoring helps maintain prediction quality.
Skills That Make a Strong Data Scientist
The strongest professionals combine technical depth with business understanding.
Technical Skills
-
SQL
-
machine learning
-
statistics
Business Skills
-
problem framing
-
decision analysis
-
stakeholder communication
-
strategic thinking
Human Skills
-
storytelling
-
curiosity
-
critical thinking
-
collaboration
Companies increasingly value professionals who can explain insights clearly rather than only building models.
Because employers increasingly value practical problem-solving ability, many learners combine technical study with data science certifications that include real-world projects, case studies, and hands-on analytics training.
Certifications often help bridge the gap between theoretical learning and business-focused implementation.
Why Data Science Careers Continue Growing
Organizations now compete heavily on decision speed.
Companies capable of understanding customer behavior faster often improve:
-
efficiency
-
customer retention
-
forecasting accuracy
-
operational planning
That demand continues driving growth in analytics and AI-related careers.
The U.S. Bureau of Labor Statistics projects upto 34% strong growth for data-focused occupations throughout the decade, especially in industries adopting AI-driven systems.
For professionals entering the field, understanding the full data science process provides a stronger foundation than learning isolated tools.
Final Takeaway
Raw data alone rarely creates business value. The real impact comes from understanding what the data reveals and using those insights to make better decisions. That is exactly how data scientists help organizations solve problems across industries.
By defining business goals, preparing messy datasets, identifying patterns, building predictive models, and explaining insights clearly, data scientists turn complex information into practical action. Whether it involves reducing fraud, improving customer retention, forecasting demand, or optimizing operations, the process always centers on transforming raw data into decisions businesses can trust.
As organizations continue relying on AI, analytics, and automation, the ability to convert data into meaningful business intelligence will remain one of the most valuable skills in the modern economy.
FAQ Section
What does a data scientist do with raw data?
A data scientist collects, cleans, analyzes, and models raw information to generate actionable business insights. The goal involves helping organizations improve decisions using evidence and predictive analysis.
How do data scientists make decisions?
A data scientist usually supports decision-making rather than making final business choices independently. The role provides analysis, predictions, and recommendations that guide leaders toward informed action.
What is the data science process?
The data science process typically includes:
problem definition
data collection
data cleaning
exploratory analysis
modeling
communication and deployment
Why is data cleaning important in data science?
Data cleaning improves accuracy and reliability. Poor-quality data can create misleading analysis, weak predictions, and costly business mistakes.
Which tools do data scientists use most?
Common tools include:
Python
SQL
Tableau
Power BI
TensorFlow
Scikit-learn
Pandas













