




























































Building AI Agents in 10 Easy Steps (2026 Complete Guide)
Learn how to build AI agents in 10 simple steps. A beginner-friendly 2026 guide covering planning, development, deployment, and optimization.

Quick answer overview: Building an AI agent in 2026 follows 10 structured steps: (1) define the goal and scope, (2) choose an architecture pattern, (3) select a framework, (4) connect your LLM, (5) build the tool layer, (6) design memory, (7) set up the orchestration loop, (8) add guardrails, (9) evaluate and test, and (10) deploy with monitoring. The most critical insight: over 40% of agentic AI projects are cancelled by 2027 due to poor governance — not bad models. Architecture and evaluation discipline separate agents that reach production from those that stay in pilots.
Building an AI agent used to require a research team and six months. In 2026, it requires the right ten steps and the understanding of why each one matters.
The global AI agents market has crossed $10–12 billion this year, with Gartner forecasting that 40% of enterprise applications will embed task-specific agents by year-end — up from under 5% in 2025. But the same research identifies a critical gap: only 11% of organizations that adopt agents actually run them in production. The remaining 68 percentage points are stuck in pilots, proofs-of-concept, and abandoned projects.
The failure mode is almost never the model. It is the architecture decisions made in steps 1 through 10.
This guide walks you through every step with the specificity that separates production deployments from demo-ware — the tools that matter, the mistakes that cost teams weeks, and the governance patterns that determine whether an agent ever leaves the building.
What Is an AI Agent? (A Precise Definition)
An AI agent is an autonomous software system that can perceive its environment, reason about a goal, select and use tools, take actions, and adapt its behavior based on outcomes — all without requiring human intervention at each step.
The critical distinction from a chatbot: chatbots respond to questions. Agents complete work.
AI agents operate on a continuous loop — often called the PRAR cycle (Perceive, Reason, Act, Reflect) — that allows them to:
-
Perceive the current context: user input, system state, available tools, and memory
-
Reason about the next action: decomposing complex goals into executable steps
-
Act by calling tools, APIs, databases, or other agents
-
Reflect on the outcome and adjust the next step accordingly
This loop is what makes agents fundamentally different from any prior generation of AI tooling. It is also what makes building them correctly matter more.
Step 1: Define the Goal and Scope with Precision
The most common reason AI agent projects fail is vague objectives defined at the start.
Before writing a single line of code or choosing a framework, answer these five questions in writing:
1. What specific task should this agent complete? Not "help with customer service." Instead: "Handle tier-1 support tickets by reading the user's issue, querying the knowledge base, drafting a response, and escalating to a human if the confidence score is below 0.85."
2. What does a successful outcome look like — measurably? Define your baseline metric before deployment. "Resolve 65% of tickets without human intervention" is testable. "Improve customer service" is not.
3. What are the boundaries of acceptable agent behavior? Document what the agent is explicitly not allowed to do: access financial records, modify user accounts, send external emails without approval. These boundaries become your guardrail configuration in Step 8.
4. What is the human-in-the-loop threshold? Identify every action that requires human approval before execution. Irreversible actions — sending an email, deleting a record, completing a transaction — should always require explicit approval until the agent has proven its reliability.
5. How will you know if the agent is failing silently? The most dangerous failure mode in production is an agent that appears to be working but is producing wrong outputs with confidence. Define your monitoring signals now.
Why this step is non-negotiable: Forrester's analysis of agent failures finds that the primary cause is ambiguity and unclear success criteria — not model limitations or technical failures. The organizations cancelling projects in 2027 are the ones that skipped this step in 2026.
Step 2: Choose the Right Architecture Pattern
In 2026, three architecture patterns dominate production agentic AI deployments. Choosing the wrong one for your use case is the second most common source of project failure.
Pattern A: ReAct (Reasoning + Acting)
The ReAct pattern is the starting point for most agent builds and the most battle-tested architecture in production. The agent alternates between reasoning steps (thinking through the problem) and action steps (calling tools), iterating until the goal is reached.
Best for: Single-domain tasks with clear tool boundaries — research assistants, code review bots, customer service triage.
Start here if: You are new to agent development. ReAct has the best framework support, the most learning resources, and teaches you the fundamental agent loop before you encounter its limitations.
Pattern B: Plan-and-Execute
The agent creates a full plan first, then executes each step. Faster than ReAct for long tasks, but less adaptive when the environment changes mid-execution.
Best for: Structured workflows with predictable steps — report generation, data processing pipelines, scheduled operations.
Pattern C: Multi-Agent Orchestration
Multiple specialized agents — each with a defined role — coordinate to complete tasks too complex for any single agent. An orchestrator agent receives the high-level goal and delegates to specialists: a researcher, a coder, an analyst, a governance monitor.
Best for: Complex cross-functional workflows in healthcare, finance, supply chain, and software engineering.
The common mistake: Teams jump straight to multi-agent systems because they sound more powerful. This almost always adds unnecessary complexity. Start with a single agent using ReAct. Multi-agent systems are the right answer for a specific class of problem, not the default architecture.
Step 3: Select the Right Framework
In 2026, five frameworks dominate production agent development. Each optimizes for a different set of trade-offs.
LangGraph
GitHub stars: 33,900+ | Monthly downloads: 34.5 million
LangGraph is the framework of choice when you need stateful multi-step workflows, human-in-the-loop approvals, or complex branching logic. Its graph-based orchestration gives developers fine-grained control over exactly what the agent does at each step and why — which makes it the preferred choice for compliance-sensitive applications.
Companies running LangGraph in production include Cisco, Uber, LinkedIn, BlackRock, and JPMorgan. Klarna's customer support bot, built on LangGraph, handles two-thirds of all customer inquiries — work that previously required 853 employees — saving the company $60 million annually.
Choose LangGraph when: You need auditability, complex state management, or human approval gates.
CrewAI
CrewAI maps agent roles to human team roles — a researcher, a writer, an editor — and is designed for rapid prototyping of multi-agent systems. Its role-based structure makes it intuitive for teams thinking about agent responsibilities in human terms.
Choose CrewAI when: You're building a multi-agent system and want to get to a working prototype quickly.
AutoGen (Microsoft)
AutoGen specializes in asynchronous multi-agent coordination, where agents need to operate in parallel and pass context between each other. Strong native integration with the Microsoft enterprise stack.
Choose AutoGen when: Your organization is Microsoft-heavy and you need parallel agent execution.
OpenAI Agents SDK
Released in early 2026 with explicit MCP compatibility and provider-agnostic support for 100+ LLMs. Lightweight, with built-in guardrails and comprehensive tracing capabilities. 26,000+ GitHub stars.
Choose the OpenAI Agents SDK when: You want minimal overhead, strong monitoring out of the box, and flexibility on model choice.
LangChain
The original Swiss Army knife for LLM application development. Excellent for rapid prototyping and learning — massive community, extensive documentation, broad tool support. Less suited for production-grade state management than LangGraph.
Choose LangChain when: You are learning agent development or need to prototype quickly before committing to an architecture.
Framework selection reality check: The framework you choose affects how much control you have over agent behavior, how observable your agent is in production, and how painful your next migration will be. Choose based on your production requirements, not which framework has the most GitHub stars. Open-source frameworks give you control and avoid vendor lock-in — a meaningful advantage as the market continues consolidating.
Step 4: Connect Your LLM
The language model is the reasoning engine of your agent. Selecting and connecting it correctly affects capability, cost, latency, and reliability.
Choosing a Model
In 2026, the major production-capable models include offerings from Anthropic (Claude), OpenAI (GPT series), Google (Gemini), and Meta (Llama, open-source). The selection criteria that matter for agents specifically:
-
Multi-step reasoning quality: Can the model maintain coherent chains of reasoning across 20+ decision points?
-
Tool-calling reliability: Does the model produce well-structured function calls with accurate parameter formatting?
-
Context window size: Gemini 1M+ tokens, Claude 200K. Bigger windows help but do not eliminate the need for memory architecture (more on this in Step 6).
-
Hallucination rate at the task level: Error rates have dropped from 8–12% in early 2025 to 3–5% by Q4 2025 — but they have not reached zero. Choose a model whose error profile matches your tolerance.
Using a Gateway Layer
In production, connect to your LLM through a gateway layer rather than directly. The gateway handles model routing, budget caps, retry logic on provider outages, and request logging for cost auditing. Leading options in 2026 include LiteLLM (open-source), OpenRouter, Vercel AI Gateway, and Portkey.
This one architectural decision — adding a gateway — gives you the ability to swap models without touching your agent code, enforce spend limits before they become incidents, and maintain a complete audit trail of every model call.
Step 5: Build the Tool Layer
Tools are what transform an LLM from a text generator into an agent that takes action in the world. This is where agents gain their hands.
What Tools Do
A tool is any external capability the agent can call: a web search API, a database query, a code executor, an email sender, a calendar event creator. When the agent decides it needs information or needs to take an action it cannot handle from memory alone, it calls the appropriate tool, receives the result, and incorporates it into its next reasoning step.
Model Context Protocol (MCP): The Standard That Changed Everything
Before Anthropic introduced the Model Context Protocol (MCP) in November 2024, connecting an agent to external tools required custom integration code for every tool-agent pair — an unsustainable N×M problem as both agent and tool ecosystems grew.
MCP solves this with a universal interface: each agent speaks MCP, each tool exposes an MCP server, and any compliant agent can use any compliant tool without bespoke integration code. This collapses the integration problem to N+M.
As of mid-2026, MCP has crossed 97 million monthly SDK downloads and supports 1,000+ servers in its ecosystem. It has been adopted by Anthropic, OpenAI, Google, Microsoft, and Amazon as the cross-industry standard. Enterprise vendors including Atlassian, Salesforce, and SAP now ship production-grade MCP connectors for their platforms.
The practical impact: A developer building an agent in 2026 can connect to Jira, GitHub, Slack, a PostgreSQL database, and a web browser with a fraction of the integration work required 18 months ago.
Tool Design Principles
Validate inputs and outputs. Treat every tool as an API with a strict contract. Validate the structure of inputs before calling and outputs before incorporating into the agent's reasoning.
Make side effects idempotent. An agent that retries a failed action should not create duplicate records, send duplicate emails, or double-process transactions. Design tools that can safely be called more than once for the same operation.
Budget time and cost per tool call. Without explicit limits, an agent that encounters errors can enter retry loops that consume both time and API credits. Set maximum retry counts and timeout thresholds for every tool.
Start with read tools before write tools. Tools that read information are low-risk. Tools that write, send, or delete are high-risk. Build and validate your agent's reasoning with read-only tools first. Add write tools only after you have established baseline reliability.
Step 6: Design the Memory Architecture
Memory is what separates an intelligent agent from a stateless function that forgets everything between calls. In 2026, memory has become a first-class architectural primitive — not an afterthought bolted onto a vector database.
The AI agent memory market has reached $6.27 billion in 2026, projected to grow to $28.45 billion by 2030 at a 35% CAGR. That growth reflects an industry-wide recognition: the model is not the product. The memory is.
The Four Memory Types
Short-term memory (Working memory) Holds the current task state and session context. Stored in a fast cache (Redis is the standard for sub-1ms latency). Discarded at the end of a session. This is what the agent "knows" right now.
Long-term memory (Semantic memory) Persistent domain knowledge — product documentation, company policies, validated facts — stored in a vector database optimized for semantic similarity retrieval. Qdrant, Pinecone, and Weaviate are the most common choices in production. Semantic chunking improves retrieval accuracy by up to 40% compared to fixed-size methods (Authority Partners, 2026).
Episodic memory (Interaction history) A time-ordered record of the agent's decisions, tool calls, and outcomes across sessions. This enables cross-session continuity — the ability to "remember what we decided yesterday." Without episodic memory, every session starts from scratch. With it, the agent becomes genuinely adaptive over time.
Tool memory (Procedural memory) Function schemas, API specifications, and capability registries. Stores what tools the agent has access to and how to call them correctly.
The Three Memory Failure Modes to Avoid
Hallucination amplification: Stale memory retrieved as ground truth. If your vector database contains outdated information, the agent will confidently act on it. Implement regular re-indexing and version-aware retrieval.
Retrieval drift: An embedding model upgrade without re-indexing produces geometrically misaligned retrieval — the queries and the stored embeddings no longer live in the same semantic space. This produces no error messages. It just returns wrong results.
Context window overflow: Unmanaged memory accumulation fills the context window, crowding out the agent's current reasoning. The agent forgets what it learned in step 3 by step 17. Even with large context windows (Gemini's 1M+ tokens, Claude's 200K), memory management remains a non-trivial engineering problem.
The common mistake: Most production agents in 2026 have no memory architecture. They have a RAG pipeline — retrieve context at query time from a flat vector collection, discard it after the response. This is a starting point, not a solution. A production memory architecture has four distinct layers, each with an appropriate storage backend, retrieval strategy, and invalidation policy.
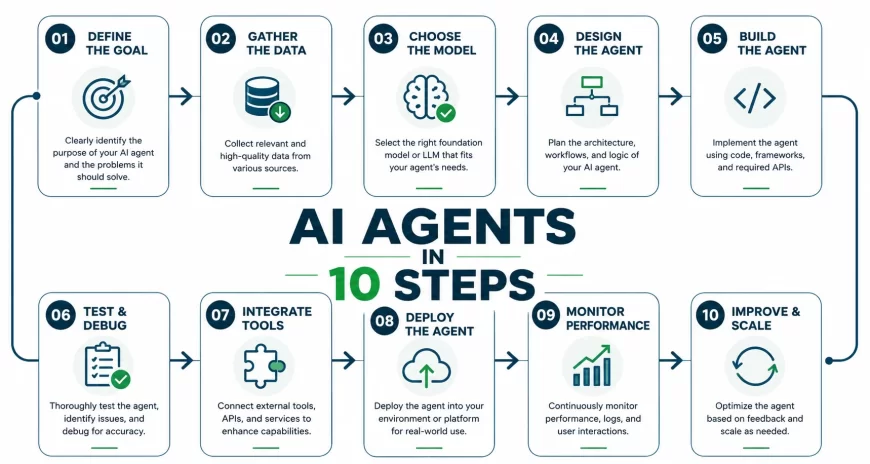
Step 7: Build the Orchestration Loop
The orchestration layer is the control system of your agent — the infrastructure that decides when to reason, when to act, when to wait for human input, and when to stop.
Frameworks like LangGraph, AutoGen, and CrewAI operate at this layer. The orchestration loop handles:
Goal decomposition: Breaking a high-level objective into a sequence of concrete, executable steps. The quality of this decomposition is often the primary determinant of agent performance on complex tasks.
State management: Tracking what the agent has done, what intermediate results it holds, and what it needs to do next. LangGraph's graph-based state machine is the current standard for applications that require auditability and resumability.
Error handling and retry logic: Agents fail. Tools time out. APIs return errors. A production orchestration layer catches failures gracefully, retries with appropriate backoff, and escalates to human oversight when retries are exhausted.
Human-in-the-loop gates: Every irreversible action should pass through a defined approval mechanism before execution. Not because agents are untrustworthy, but because trust is earned incrementally through demonstrated reliability on progressively higher-stakes decisions.
Multi-agent coordination: If you are using a multi-agent architecture, the orchestration layer manages the communication between the orchestrator and specialist agents — routing tasks, aggregating outputs, and handling coordination failures.
Practical advice from the O'Reilly AI Agents Stack 2026 report: "Build evals before you deploy, because these agents break silently." The orchestration layer is where you instrument observability — traces, logs, decision points — that make it possible to understand why an agent did what it did. Without traces, you cannot debug or improve agent behavior.
Step 8: Add Guardrails
A production AI agent makes thousands of decisions per hour. Some of those decisions will be wrong. Guardrails are the system that catches wrong decisions before they reach users, external systems, or regulatory auditors.
Deloitte's 2026 AI report found that only 20% of organizations have mature AI governance models. This is precisely why over 40% of agentic AI projects are at risk of cancellation — governance is being treated as an afterthought rather than a design requirement.
The Three Guardrail Layers
Layer 1: Input screening Validate and filter all inputs before they reach the agent. Block prompt injection attacks (attempts to override the agent's instructions through malicious input), PII that should not enter the processing pipeline, and inputs that fall outside the agent's defined scope.
Layer 2: Behavioral constraints Policy-as-code that defines what actions the agent is and is not permitted to take. An agent that should never access financial records should have that constraint enforced at the execution layer — not just mentioned in the system prompt.
Layer 3: Output validation Verify agent outputs before they reach downstream systems. Structural failures — malformed JSON, missing required fields, wrong data types — cause crashes in production. Semantic failures — hallucinated facts presented with confidence — erode user trust over time. Validate both.
The Deployment Sequence for Guardrails
Week 1–2: Monitor mode. Run guardrails on all traffic without blocking. Log what would have been blocked. Analyze false positive rates. This prevents guardrails from blocking legitimate outputs during the tuning phase — a common reason teams abandon guardrails entirely.
Week 3–4: Soft enforcement. Block clearly unsafe outputs (prompt injection attempts, PII leakage). Let borderline cases through with flags. Review flagged outputs daily.
Month 2+: Full enforcement. Block all validation failures. Set up retry logic for structural failures. Route critical blocks to human review queues.
Security note for 2026: Agent guardrails are a different discipline from LLM guardrails. In 2024, guardrails meant input/output filters on a model. In 2026, your agent calls tools, spends money, and takes actions with real-world consequences. Every agent should have a clear identity, limited and audited access permissions, managed data outputs, and protection from external attacks. Agents without these safeguards become attack surfaces.
Step 9: Evaluate Before You Deploy
The single most common cause of production failures is shipping agents that have not been properly evaluated. Guardrails catch what you know to look for. Evaluation discovers what you didn't know to look for.
What to Evaluate
Tool call accuracy: Did the agent call the right tool? With the right parameters? In the right sequence?
Output correctness: Is the agent's final output factually accurate and relevant to the original goal?
Goal completion rate: What percentage of tasks does the agent complete successfully without human intervention?
Failure mode distribution: When the agent fails, how does it fail? Does it hallucinate confidently? Loop indefinitely? Produce structurally valid but semantically wrong outputs?
Cost and latency per task: What does a successful agent run cost in API tokens? How long does it take? Both metrics need baselines before deployment.
Evaluate Full Trajectories, Not Just Final Outputs
The critical insight from production evaluation in 2026: evaluate the agent's reasoning path, not just its answer.
An agent that reaches the right answer via the wrong reasoning is fragile — it will fail on slightly different inputs. An agent that follows the right reasoning steps even when it makes a minor error is robust — you can fix the error without redesigning the architecture.
Evaluate: tool choice correctness at each step, argument validity for each tool call, step count efficiency, and policy compliance throughout the trajectory.
The Evaluation Toolchain
Leading evaluation platforms in 2026 include LangSmith (native to LangGraph), Braintrust (with its loop-powered evaluation and one-click test case generation from production traces), and Galileo (with real-time guardrail integration). Most export OpenTelemetry traces, providing flexibility to switch observability providers without rebuilding your test infrastructure.
A practical truth from the O'Reilly AI Agents Stack: "The prototype-to-production gap is the biggest of any layer. Most prototypes have zero eval. You don't feel the pain until production users find the failures for you." Run evaluation before you deploy. Not after.
Step 10: Deploy with Monitoring
Getting an agent to production is step 10, not the finish line. Production is where you discover the failure modes that evaluation did not surface — and where governance earns its value.
Monitoring vs. Traditional Application Monitoring
Traditional application monitoring tracks system health: CPU usage, memory, request rates, error rates, latency. All of this still applies to agents. But agent monitoring adds a layer that traditional monitoring does not have: behavioral monitoring.
You need to track not just whether the agent responded, but whether it responded correctly. Whether its reasoning was coherent. Whether it used the tools it was supposed to use, in the order it was supposed to use them, with the parameters they required.
What to Monitor in Production
Trace-level visibility: Every agent run should produce a complete trace — the sequence of reasoning steps, tool calls, inputs, outputs, and decision points — that can be replayed and inspected. Without traces, debugging a production failure is archaeology.
Guardrail trigger rates: Track how often each guardrail fires. A sudden spike in a specific guardrail is an early warning signal — either the agent's behavior is changing or the environment it operates in has changed.
Cost per task over time: Agent API costs can drift significantly as task complexity changes. Set budget alerts before they become billing surprises.
Human escalation rate: The percentage of tasks escalated to human review is one of your most informative health metrics. An escalation rate trending up means the agent is encountering situations it was not designed for. An escalation rate trending toward zero means you may be ready to expand the agent's scope.
Latency per step: Identify which tools or reasoning steps are creating bottlenecks. In multi-agent systems, one slow specialist can block the entire orchestration.
Scaling Progressively
Week 1–4: Single-user or internal-only deployment. Collect traces, identify edge cases, tune guardrails.
Month 2: Expand to a limited user group. Monitor escalation rates and failure modes at scale.
Month 3+: Broad deployment, with continuous evaluation integrated into your CI/CD pipeline so that every code change is tested against your established evaluation suite before reaching production.
Common Mistakes and How to Avoid Them
These patterns appear consistently in failed agent projects. Knowing them in advance is the closest thing to a shortcut in agent development.
Mistake 1: Adding too many tools too early. More tools mean more ways the agent can make a wrong decision. Start with the minimum viable tool set and add tools only when their absence is the proven constraint on agent performance.
Mistake 2: Skipping memory architecture. A stateless agent that forgets everything between interactions is not an agent — it is an expensive chatbot. Design your memory layer before you design your orchestration loop.
Mistake 3: Building multi-agent systems before you need them. Single-agent systems are faster to build, easier to debug, and easier to govern. Start with one agent. Add agents when you have a specific coordination problem that a single agent genuinely cannot solve.
Mistake 4: Trusting the demo, not the trajectory. Agents that look impressive in demos often fail on edge cases. Always evaluate on a diverse set of realistic inputs — including inputs that are ambiguous, incomplete, or adversarial.
Mistake 5: Treating guardrails as optional. Operating production agents without guardrails exposes your organization to security incidents, compliance violations, and eroded confidence in AI investment. Guardrails are not constraints on capability. They are the prerequisite for sustainable deployment.
Mistake 6: Deploying without observability. You cannot debug what you cannot see. If your agent fails silently in production, you will find out from a user complaint, not a monitoring alert. Instrument traces before you deploy, not after.
The 10 Steps at a Glance
|
Step |
What You're Building |
Why It Matters |
|
1 |
Clear goal and scope |
Vague objectives cause 40%+ of project failures |
|
2 |
Architecture pattern |
ReAct → multi-agent, not the reverse |
|
3 |
Framework selection |
Control, observability, and migration flexibility |
|
4 |
LLM connection via gateway |
Model swapping, budget control, audit trail |
|
5 |
Tool layer with MCP |
Agents gain the ability to act in the world |
|
6 |
Memory architecture (4 types) |
Persistence, context, and cross-session continuity |
|
7 |
Orchestration loop |
Goal decomposition, error handling, human gates |
|
8 |
Guardrails (3 layers) |
Governance before deployment, not after |
|
9 |
Evaluation of full trajectories |
Find what you didn't know to look for |
|
10 |
Production monitoring |
Behavioral visibility, not just system health |
Frequently Asked Questions
What is the easiest way to build an AI agent in 2026?
The fastest path from zero to a working agent is: choose CrewAI or LangChain (both beginner-friendly with strong documentation), connect to an LLM via the OpenAI or Anthropic API, define two or three read-only tools, and implement the ReAct pattern. Do not start with multi-agent systems. Start simple, validate the core loop works, then expand.
What is the best framework for building AI agents?
It depends on your use case. LangGraph is the production standard for stateful, auditable workflows (preferred by JPMorgan, BlackRock, Klarna). CrewAI is fastest for multi-agent prototyping. The OpenAI Agents SDK offers the lowest overhead with strong monitoring. For beginners: LangChain or CrewAI. For production: LangGraph.
What is Model Context Protocol (MCP) and do I need it?
MCP is the open standard — introduced by Anthropic and now adopted by OpenAI, Google, and Microsoft — that lets any compliant agent connect to any compliant tool without custom integration code. With 97 million monthly downloads and 1,000+ servers, it is effectively the TCP/IP of the agentic layer. If you are building any agent that needs to connect to external tools or data sources, yes, you need it. All five major frameworks now treat MCP as the default tool integration layer.
How long does it take to build an AI agent?
A simple single-agent system with two to three tools and no persistent memory: one to two weeks for a developer familiar with Python and LLM APIs. A production-grade agent with memory architecture, guardrails, evaluation infrastructure, and monitoring: one to three months. A multi-agent system with orchestration, human-in-the-loop controls, and enterprise integrations: three to six months depending on the complexity of the target workflows.
Why do so many AI agent projects fail?
Gartner projects over 40% of agentic AI projects will be cancelled by the end of 2027. The consistent failure pattern: unclear success criteria (Step 1), missing evaluation (Step 9), and absent governance (Step 8). The model is rarely the problem. The architecture and the organizational disciplines around it almost always are.
Do I need to know how to code to build an AI agent?
For the approach described in this guide: yes, Python knowledge is required. However, no-code agent builders (including Salesforce Agentforce, Microsoft Copilot Studio, and visual tools like n8n and Zapier) allow non-developers to configure and deploy simpler agents without writing code. For production-grade systems with custom tool integration and memory architecture, code is currently unavoidable.
How IABAC Certification Prepares You to Build Agents
Understanding the 10 steps conceptually is the starting point. Building agents that reach production — and leading teams that do — requires a deeper foundation: how LLMs reason, how memory and retrieval systems work, how to evaluate AI outputs rigorously, and how to govern autonomous systems responsibly.
These are not skills you develop by reading tutorials. They are skills built through structured, assessed learning that covers AI fundamentals, system architecture, and practical deployment — the curriculum that IABAC programmes are built around.
IABAC Certified Artificial Intelligence Expert (CAIE) covers the technical depth needed to design, build, and evaluate AI agent systems — from LLM mechanics and tool integration to memory architecture and evaluation frameworks.
IABAC Artificial Intelligence Certified Executive (AICE) is designed for leaders who need to direct AI agent initiatives, govern autonomous systems, and make informed decisions about architecture and risk — without needing to write the code themselves.
Both certifications are globally recognised credentials that signal verified, assessed competency — not self-reported familiarity. As agentic AI embeds itself in enterprise workflows, the credential gap between AI-literate and AI-unfamiliar professionals is becoming a measurable career variable.
Explore the full IABAC AI certification programmes or the Artificial Intelligence complete guide to find the structured learning path that matches your current level and goals.
Sources Referenced
-
Gartner: 2026 Hype Cycle for Agentic AI; enterprise application embedding forecast; project cancellation projection
-
O'Reilly: The AI Agents Stack 2026 Edition (agentic architecture patterns, eval, memory)
-
Firecrawl: Best Open Source Agent Frameworks 2026 (LangGraph, CrewAI, OpenAI SDK adoption data)
-
Anthropic: Model Context Protocol specification; MCP adoption data (97M downloads, 1,000+ servers)
-
Deloitte: 2026 AI governance maturity report (20% mature governance)
-
Authority Partners: AI Agent Guardrails Production Guide 2026 (semantic chunking 40% accuracy improvement)
-
AI Magicx: AI Agent Memory Architecture Developer Guide 2026 (memory market $6.27B; four memory types)
-
ToolHalla: AI Agent Guardrails & Output Validation 2026 (deployment sequence, failure modes)
-
Braintrust: AI Observability Tools Buyer's Guide 2026
-
JetBrains: Top Agentic Frameworks 2026 (PRAR cycle, framework comparisons)
-
Knowlee: AI Agent Platform Architecture 2026 (gateway layer patterns)
-
First Page Sage: Agentic AI Adoption Statistics Feb–Jun 2026
-
Digital Applied: Agentic AI Statistics 2026 — 150+ Data Points Collection (79% adoption, 11% production gap)
This article is part of IABAC's technical content series on AI Applications & Technologies. See also:
-
Why 2026 Is the Year of AI Agents — the strategic context for everything in this guide
-
Agentic AI Takes Over: 11 Shocking 2026 Predictions — the data behind the shift













