





























































What Is Retrieval-Augmented Generation (RAG)?
Retrieval-augmented generation combines AI models with real-time data retrieval to deliver accurate, source-backed responses for enterprise applications.

Artificial intelligence can write, summarize, and answer questions at impressive speed. But it has a serious problem: it sometimes makes things up and presents them as facts. This is called hallucination, and it is a real barrier to trusting AI in critical situations.
Retrieval-augmented generation, or RAG, is the framework that addresses this directly. It connects AI to real knowledge sources so responses are grounded in actual information, not just what the model vaguely remembers from training.
Here’s how retrieval-augmented generation actually works.
What Is Retrieval-Augmented Generation?
Retrieval-augmented generation, commonly referred to as RAG, is an AI framework that combines two core capabilities: information retrieval and text generation. It was introduced by researchers at Facebook AI (now Meta AI) in a 2020 research paper titled Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, published on arXiv, one of the leading platforms for sharing AI research.
RAG works by connecting a large language model to an external knowledge source.
When a user asks a question, the system first retrieves relevant documents or data from a knowledge base, then passes that information to the language model along with the original query. The model then uses both the retrieved content and its own trained knowledge to generate a well-informed, accurate response.
Think of it this way: instead of asking someone to answer a question entirely from memory, you first hand them the relevant book, article, or document and then ask them to answer it. The answer becomes far more reliable because it is grounded in actual source material.
Why Was RAG Created?
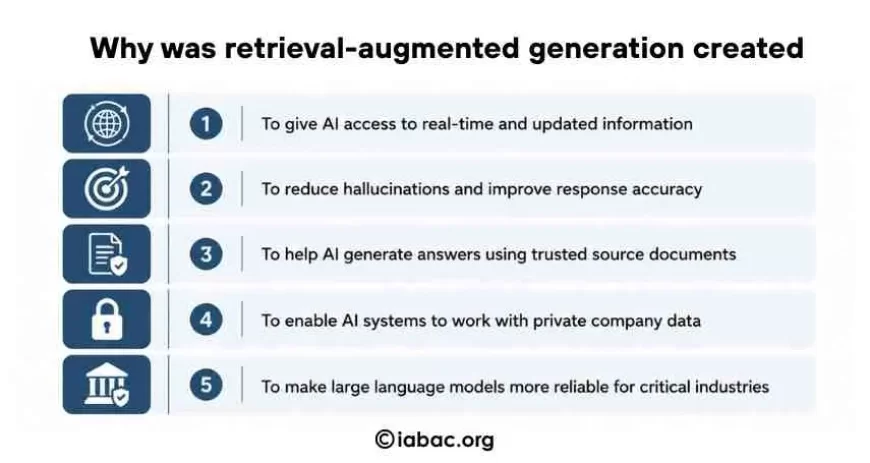
To understand why retrieval-augmented generation was developed, it helps to understand the core limitations of traditional large language models.
LLMs are trained on massive datasets collected up to a certain point in time. Once training is complete, the model's knowledge is frozen. It cannot access new information unless it is retrained, which is an expensive and time-consuming process. This creates several problems:
Knowledge Cutoffs: An LLM trained with data up to a certain date will not know about events, research, or developments that happened after that point. This makes it unreliable for time-sensitive queries.
Hallucination: When a model does not have accurate information on a topic, it sometimes generates reasonable-sounding but incorrect answers. This is a major concern in fields like healthcare, law, and finance, where accuracy is non-negotiable.
Lack of Source Transparency: Standard LLMs do not cite sources. Users have no way to verify where the information came from, which reduces trust in the output.
Inability to Access Private Data: Organizations often need AI to work with their own internal documents, databases, and files. A general-purpose LLM has no way to access this proprietary information.
RAG was designed to address all of these limitations by giving language models the ability to fetch relevant, current, and domain-specific information before generating a response.
How Does Retrieval-Augmented Generation Work?
RAG involves several steps that happen in sequence every time a user submits a query. Here is a step-by-step breakdown of the process:
Step 1: User Submits a Query
The process begins when a user asks a question or makes a request. This could be anything from "What are the latest treatment options for Type 2 diabetes?" to "Summarize our Q3 sales report."
Step 2: Query Is Converted Into an Embedding
The query is transformed into a numerical representation called a vector embedding. This captures the semantic meaning of the query, not just the keywords, allowing the system to find content that is conceptually related even if it does not use the exact same words.
Step 3: Retrieval From a Knowledge Base
The embedding is used to search a vector database or document store. The system retrieves the most relevant parts of text, documents, or data based on similarity to the query. This is the retrieval component in action.
Step 4: Retrieved Content Is Added to the Prompt
The retrieved documents or text chunks are appended to the original query and passed into the language model as context. This is called augmentation.
Step 5: The Model Generates a Response
With both the user's query and the retrieved context available, the LLM generates a response. Because the model now has access to relevant, specific information, its output is more accurate, more detailed, and grounded in real sources.
Step 6: Response Is Delivered to the User
The final response is returned to the user. In many RAG implementations, the system also provides citations or references to the source documents, allowing users to verify the information directly.
Key Components of a RAG System
A retrieval-augmented generation system is made up of several important components working together:
Document Store or Knowledge Base: This is the collection of documents, files, databases, or web pages that the system retrieves from. It can include internal company documents, product manuals, research papers, support tickets, or any structured or unstructured content.
Embedding Model: An embedding model converts both the user query and the documents in the knowledge base into vector representations. Popular options include OpenAI's text-embedding models, Cohere Embed, and open-source alternatives like Sentence Transformers.
Vector Database: A vector database stores the embeddings of all documents and enables fast similarity search. When a query comes in, the database finds the most semantically similar content. Popular vector databases include Pinecone, Weaviate, Chroma, and FAISS.
Retriever: The retriever queries the vector database and returns the most relevant document chunks. Retrieval strategies include dense retrieval, sparse retrieval, and hybrid approaches that combine both methods.
Large Language Model: The LLM is the generation engine. It takes the query and the retrieved context and produces a coherent, accurate response. Common LLMs used in RAG systems include GPT-4, Claude, Mistral, and LLaMA.
Orchestration Layer: Frameworks like LangChain, LlamaIndex, and Haystack connect all these components and manage the flow of data through the pipeline.
RAG vs Fine-Tuning: What Is the Difference?
One of the most common questions about this framework is how it compares to fine-tuning. Both approaches aim to make LLMs more useful for specific tasks or domains, but they work in fundamentally different ways.
Fine-tuning involves taking a pre-trained model and training it further on a custom dataset. This bakes domain-specific knowledge directly into the model's weights. It works well for tasks where the style, tone, or structure of output needs to match a specific pattern, but it is expensive, requires technical expertise, and cannot easily incorporate new information once training is complete.
Retrieval-augmented generation, on the other hand, keeps the base model intact and simply provides it with relevant information at the time of inference. As a result, organizations can update knowledge sources without retraining the model, making RAG significantly more flexible and cost-effective.
In many production systems, RAG and fine-tuning are used together. The model is fine-tuned for a specific task or domain, and RAG is layered on top to provide access to current, specific information.
Advantages of Retrieval-Augmented Generation
This AI framework offers several compelling advantages over standard LLM usage:
Reduced Hallucination: Because the model is working with actual retrieved content, it is far less likely to fabricate information. The responses are grounded in real documents rather than statistical patterns alone.
Access to Current Information: Unlike a static LLM, a RAG system can retrieve the latest information from an updated knowledge base, making it suitable for time-sensitive applications.
Source Attribution: RAG systems can provide references to the documents they retrieved, making it easier for users to verify facts and trust the output.
Cost Efficiency: Updating a knowledge base is significantly cheaper than retraining a large language model. Organizations can keep their AI system current without major infrastructure costs.
Domain Customization: RAG makes it easy to build AI applications tailored to specific industries or organizations by simply pointing the retriever at domain-specific content.
Privacy and Data Control: Organizations can use RAG with internal, private data without exposing that information to public model training pipelines.
Limitations of Retrieval-Augmented Generation
While this is a powerful framework, it is not without its challenges:
Retrieval Quality Matters: If the retriever pulls in irrelevant or low-quality documents, the generated response will also be poor. The quality of the output is heavily dependent on the quality of the retrieval step.
Chunking Challenges: Documents need to be split into chunks before being stored in a vector database. If the chunking strategy is too coarse or too fine, it can hurt retrieval accuracy significantly.
Latency: RAG adds an extra retrieval step before generation, which increases response time compared to a standard LLM call.
Context Window Limits: LLMs have a limited context window. If too many documents are retrieved, they may exceed this limit, requiring the system to truncate or prioritize content.
Complexity: Building and maintaining a RAG pipeline requires more infrastructure and expertise than simply calling an LLM API directly.
Real-World Applications of Retrieval-Augmented Generation
Retrieval-augmented generation is already being deployed across a wide range of industries. Here is a look at where it is making the most impact, backed by real examples.
1. Healthcare: Diagnostic Support and Clinical Decision-Making
In healthcare, RAG is helping clinicians make faster and more informed decisions. RAG systems assist medical professionals by combining patient-specific insights with the latest medical literature, enabling more evidence-based diagnoses.
A systematic review published in the journal AI (2025) analyzed 30 peer-reviewed studies on RAG in clinical domains and found it most effective in three areas: diagnostic support, electronic health record summarization, and medical question answering.
2. Finance: JPMorgan Chase and Enterprise AI
JPMorgan Chase has explicitly highlighted RAG as a key technology for integrating private data into model responses as part of its broader AI infrastructure strategy.
The bank had over 450 AI use cases in development with a $17 billion technology budget in 2024, covering applications from client advisory automation and fraud detection to call center optimization.
AI-enhanced tools contributed to a 20% increase in gross sales in asset and wealth management between 2023 and 2024.
3. Customer Support: Personalized and Accurate Responses
In customer service, RAG assists by sourcing product information and customer history to generate personalized responses, improving both the efficiency and quality of support interactions.
Practical applications include customer support chatbots, enterprise Q&A systems, and AI assistants, all of which measurably improve workflows and productivity across organizations.
4. Retail and E-Commerce: Personalization at Scale
The retail and e-commerce sector uses RAG for personalization and better customer engagement. For retail businesses, it helps to analyze sales data, track trends, and provide customers with more relevant and timely product information.
Document retrieval systems powered by RAG help these businesses make data-driven decisions by pulling real-time, current information from proprietary and external databases on demand.
5. Automotive: Toyota's Dealership AI Assistant
Toyota Motor North America and Toyota Connected built a generative AI platform using RAG to help dealership sales staff and customers access accurate vehicle information in real time.
The problem they were solving was clear: customers often arrived at dealerships highly informed from internet research, while sales staff lacked quick access to detailed vehicle specifications. trim options and pricing. RAG bridged that gap effectively.
The Future of Retrieval-Augmented Generation
This framework is still a rapidly evolving area of AI research and development. Several trends are shaping where it is headed:
Advanced Retrieval Techniques: Methods like query expansion, hypothetical document embeddings (HyDE), and reranking are improving the accuracy and relevance of retrieved content with every iteration.
Multimodal RAG: Researchers are extending RAG beyond text to include images, audio, and video, enabling richer and more versatile AI applications across industries.
GraphRAG: Microsoft and other organizations are experimenting with graph-based retrieval, where knowledge is stored in structured graph databases to capture relationships between concepts more effectively than flat vector search.
Agentic RAG: RAG is being combined with AI agents that can autonomously decide when and what to retrieve, plan multi-step tasks, and interact with external APIs and tools in dynamic workflows.
Enterprise-Grade RAG: Modern RAG systems now support multimodal retrieval, real-time data pipelines, and privacy-preserving features, making them suitable for large-scale enterprise environments with strict compliance requirements.
As retrieval-augmented generation becomes a core component of enterprise AI, professionals who want to stay ahead can learn this from structured AI certifications.
Retrieval-augmented generation represents a significant step forward in making AI systems more reliable, accurate, and useful in the real world. By combining the generative power of large language models with the precision of information retrieval, RAG addresses some of the most critical limitations of traditional AI, including hallucination, knowledge cutoffs, and lack of transparency.
Whether you are building a customer support tool, a legal research assistant, or an internal knowledge management system, it provides a practical and scalable framework for delivering AI that people can actually trust. As the technology matures and new techniques continue to emerge, RAG will remain one of the most important architectures in the AI landscape.












